Content Recommendation From Links Shared on Twitter Using Neo4j and Python
William Lyon
May 28, 2015
18 min read
Overview#
I've spent some time thinking about generating personalized recommendations for articles since I began working on an iOS reading companion for the Pinboard.in bookmarking service. One of the features I want to provide is a feed of recommended articles for my users based on articles they've saved and read. In this tutorial we will look at how to implement a similar feature: how to recommend articles for users based on articles they've shared on Twitter.
Tools#
The main tools we will use are Python and Neo4j, a graph database. We will use Python for fetching the data from Twitter, extracting keywords from the articles shared and for inserting the data into Neo4j. To find recommendations we will use Cypher, the Neo4j query language.
Neo4j#
Neo4j is a type of NoSQL database known as a graph database. Instead of tables or documents, the fundamental data type of a graph database is a graph (nodes and edges). Modeling data as a graph allows for efficiently generating recommendations by traversing the graph. If you haven't been exposed to Neo4j before check out some this material. Getting started with Neo4j is as easy as downloading the latest version here or using a hosted instance from GrapheneDB or GraphStory. There's even a Cloud Formation config for easily spinning up AWS instances here.
Python Libraries#
There are lots of great open source Python libraries available. Here are three that we'll be using:
- Tweepy - a lightweight wrapper around the Twitter API. We will use Tweepy to make authenticated requests to Twitter to search for links shared by people we follow on Twitter (our Twitter friends). Install with
pip install tweepy. - Newspaper3k - Newspaper is a library for article scraping, parsing and keyword extraction. We will use Newspaper to extract the text from the links our friends have shared on Twitter and find relevant keywords for each article. Install with
pip install newspaper3k(assuming Python 3). - Py2neo - Py2neo is a Python binding for Neo4j. We will use Py2neo to execute queries against Neo4j, mainly for data insertion. Install with
pip install py2neo.
Getting Links From Twitter Friends#
We first need some data to power our recommender system. As I mentioned earlier, this data will come from Twitter. Specifcally, we are interested in links that our friends have posted to Twitter. At a high level, what we want to do is ask Twitter for a list of all of our friends (users that we are following), then iterate through this list and for each friend find all the URLs that they have shared on Twitter (we will just make the assumption that any url shared on Twitter is an article).
To use the Twitter API we will need to create a Twitter application and generate the necessary keys for authentication. If you haven't created a Twitter application before you can find out how to do it here.
Once we have our API keys we can use Tweepy to create an authenticated Tweepy instance:
import tweepy
consumer_key = 'xxx'
consumer_secret = 'xxx'
access_token = 'xxx'
access_token_secret = 'xxx'
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth, wait_on_rate_limit = True, wait_on_rate_limit_notify = True)
We've imported the Tweepy library, declared our API tokens and authentication method and instanciated an instance of tweepy.API called api. The next step is to get a list of all our friends. We can do that with a single call to the Tweepy api instance:
ids = api.friends_ids()
ids now contains a list of Twitter user ids. To find all urls shared by our friends we'll need to ask Twitter for each friend's status (a tweet is a status in the Twitter docs) and look through each status for a url. Let's start by seeing how we can ask Twitter for our friends' tweets:
for friend in ids:
statuses = api.user_timeline(id=friend, count=200)
for status in statuses:
# Find a url in this status and do something with it
Now that we have a status we need to determine if it has a url in it. Fortunately the status model object retuned by Tweepy makes it very easy to find urls embedded in a tweet. Pictures, videos, and urls embedded in a tweet are extracted into an entities object in the status object with any urls residing in a sub object called urls. You can see the complete data format in the Twitter docs here.
for friend in ids:
statuses = api.user_timeline(id=friend, count=200)
for status in statuses:
if status.entities and status.entities['urls']:
for url in status.entities['urls']:
# now we have a url that was embedded in a tweet
Once we've found a url let's store the url and the tweet's author's username into a list, which we'll then write to a csv file to use later. The full code for fetching friends' urls and writing to the csv file looks like this:
import tweepy
consumer_key = 'xxx'
consumer_secret = 'xxx'
access_token = 'xxx'
access_token_secret = 'xxx'
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth, wait_on_rate_limit = True, wait_on_rate_limit_notify = True)
ids = api.friends_ids()
urls = []
for friend in ids:
statuses = api.user_timeline(id=friend, count=200)
for status in statuses:
if status.entities and status.entities['urls']:
for url in status.entities['urls']:
urls.append((url['expanded_url'], status.author.screen_name))
with open('urls.csv', 'w') as f:
for url in urls:
f.write(url[0] + ',' + url[1] + '\n')
f.close()
Parsing articles with Newspaper#
Now that we have some urls, the next step is to figure out what all these articles are about. We will do this using the newspaper3k Python library. Newspaper has features for scraping articles from a news site and extracting elements from each article, including the full text of the article, keywords, the authors and even any images and videos included in the article.
Here's an example:
In [1]: from newspaper import Article
In [2]: a = Article('http://www.lyonwj.com/using-neo4j-spatial-and-leaflet-js-with-mapbox/')
In [3]: a.download()
In [4]: a.parse()
In [5]: a.nlp()
In [6]: a.authors
Out[6]: ['William Lyon']
In [7]: a.keywords
Out[7]:
['lyon',
'location',
'william',
'polygon',
'mapbox',
'businessnode',
'neo4j',
'node',
'category',
'businesses',
'query',
'spatial',
'using',
'data',
'map',
'search',
'business']
In [8]: a.summary
Out[8]: 'Neo4j Spatial is a plugin for Neo4j ...'
In [9]: a.top_img
Out[9]: 'http://www.lyonwj.com/public/img/out.gif'
Let's define a function to download the article, parse it and extract the keywords and authors:
def parseURL(url):
a = Article(url)
try:
a.download()
a.parse()
a.nlp()
authors = a.authors
keywords = a.keywords
del(a)
return (authors, keywords)
except:
return (None, None)
Inserting Into Neo4j#
Once we have the keywords and authors of the article we are ready to insert everything into Neo4j. Here's the data model that we'll be working with:
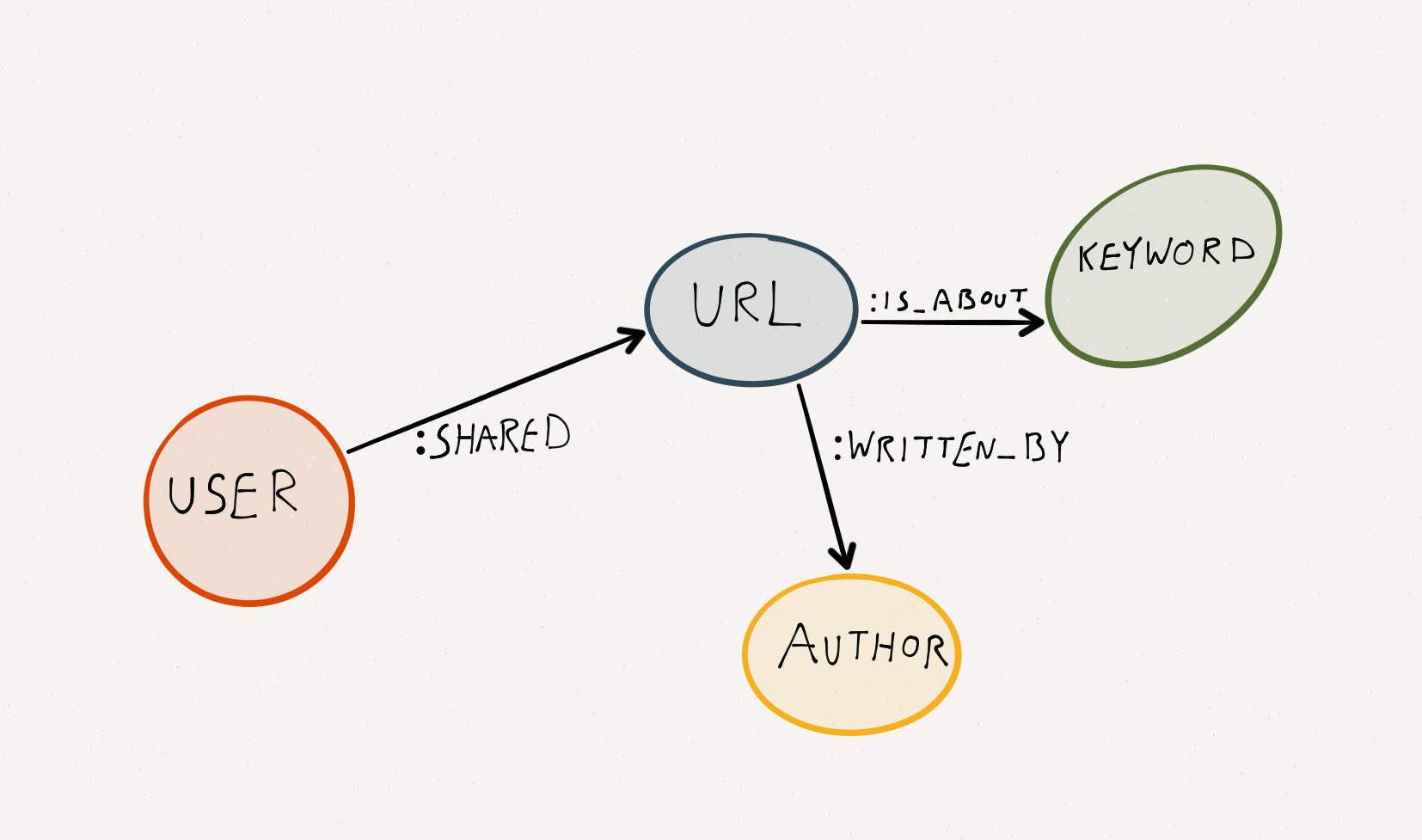
We have four nodes (User, URL, Keyword, and Author) and three edges describing the relationships between these nodes.
We will use the Python library py2neo to connect to our Neo4j instance, define the insertion Cypher query, then iterate through our list of (user, url) tuples, parsing the article for keywords at each iteration before executing the insertion Cypher query for each tuple:
graphdb = Graph('http://URL_FOR_NEO4J_SERVER_HERE/db/data')
INSERT_USER_URL_QUERY = '''
MERGE (user:User {username: {username}})
MERGE (url:URL {url: {url}})
CREATE UNIQUE (user)-[:SHARED]->(url)
FOREACH (kw in {keywords} | MERGE (k:Keyword {text: kw}) CREATE UNIQUE (k)<-[:IS_ABOUT]-(url))
FOREACH (author in {authors} | MERGE (a:Author {name: author}) CREATE UNIQUE(a)<-[:WRITTEN_BY]-(url))
'''
def insertUserURL(user, url):
authors, keywords = parseURL(url)
if authors and keywords:
params = {}
params['username'] = user
params['url'] = url
params['authors'] = authors
params['keywords'] = keywords
graphdb.cypher.execute(INSERT_USER_URL_QUERY, params)
for user, url in urls:
insertUserURL(user, url)
We've defined a parameterized Cypher query that we can reuse for each insertion. Let's break this query down line by line so we understand how it works.
First we use a MERGE statement to find or create the User node for the user that tweeted the URL. We will create (or match against, if it has already been created) a username property on the node. username is also the name of a parameter we are using to construct the query:
MERGE (user:User {username: {username}})
Next we use the same logic and use a MERGE statment to find or create the URL node for the article shared:
MERGE (url:URL {url: {url}})
Now we create a :SHARED relationship between the User node and the URL node. The CREATE UNIQUE command ensures that we are not creating duplicate relationships:
CREATE UNIQUE (user)-[:SHARED]->(url)
In this next statement keywords is an array of strings that we are passing as a parameter. We use the FOREACH command to iterate through each keyword and execute a MERGE and CREATE UNIQUE statement to create the Keyword node and the :IS_ABOUT relationship between the Keyword node and URL node. Alternatively we could have used the Cypher UNWIND command here in lieu of FOREACH:
FOREACH (kw in {keywords} | MERGE (k:Keyword {text: kw}) CREATE UNIQUE (k)<-[:IS_ABOUT]-(url))
Finally, we use a similar FOREACH command for each author of the article (these are the authors of the article, not the tweet, which is why we could have multiple):
FOREACH (author in {authors} | MERGE (a:Author {name: author}) CREATE UNIQUE(a)<-[:WRITTEN_BY]-(url))
This works, but we're spending a lot of time waiting for network requests to complete. This seems like a good opportunity to use concurreny and multi-threading so that we can process multiple articles across threads.
def doWork():
while True:
urlTuple = q.get()
insertUserURL(urlTuple[0], urlTuple[1])
q.task_done()
q = Queue(concurrent * 2)
for i in range(concurrent):
t = Thread(target=doWork)
t.daemon = True
t.start()
try:
with open('twitter_urls_friends.csv', 'r') as f:
for line in f:
l = line.split(',')
url = l[0]
user = l[1].replace('\n', '')
q.put((user, url))
q.join()
except:
pass
There's an IPython Notebook available here that has the full code for getting data from Twitter and inserting into Neo4j. Note that you'll need to insert your own Twitter API keys and Neo4j server path.
Writing Neo4j Queries#
Now that we have all our data inserted into Neo4j we can start writing queries to generate personalized recommendations of articles for our friends on Twitter.
Cypher#
Cypher is the query language for making queries to Neo4j. We've already seen it used above to insert our data into Neo4j. Now we'll use it to query our existing data. Let's start with some introductory Cypher queries to explore our data set. There are some great getting started tutorials and also the Cypher Ref Card for reference.
Exploratory Queries#
To execute Cypher queries we can use the excellent Neo4j Browser application or execute them from the command line using the Neo4j-shell. I like to use the Neo4j Browser if I want to make use of any of the graphical tools for exploring and visualizing the data set. The Neo4j-shell is useful for running queries on a remote machine where you don't want to go to the hassel of exposing the right ports for access to the browser. I'll be posting responses from both interfaces here.
I always like to start exploring a dataset by counting things. This helps me to wrap my head around the scope of the data.
How many users are in my data set?
Cypher uses pattern matching to define queries: define the pattern with ASCII art like nodes and relationships and Neo4j will return all matches of that pattern.
MATCH (u:User) RETURN count(u);
+----------+
| count(u) |
+----------+
| 318 |
+----------+
1 row
53 ms
How many articles are in the dataset?
MATCH (url:URL) RETURN count(url);
+------------+
| count(url) |
+------------+
| 6103 |
+------------+
1 row
165 ms
How many articles have I shared on Twitter?
MATCH (user:User {username: 'lyonwj'})-[:SHARED]->(u:URL)
RETURN count(u);
+----------+
| count(u) |
+----------+
| 52 |
+----------+
1 row
21 ms
Who has shared the most articles?
We can use ORDER BY and LIMIT to sort and filter our results for only the top five most prolific sharers.
MATCH (u:User)-[s:SHARED]->(URL)
WITH u, count(s) AS num
RETURN u.username AS user, num ORDER BY num DESC LIMIT 5;
+-----------------------+
| user | num |
+-----------------------+
| "macstoriesnet" | 178 |
| "jabawack" | 122 |
| "doctorow" | 121 |
| "thiakx" | 118 |
| "danfoody" | 105 |
+-----------------------+
5 rows
180 ms
How many articles does each user share on average?
Cypher also has the standard mathematical functions for computing sum, average, standard deviation, etc.
MATCH (u:User)-[s:SHARED]->(URL)
WITH u, count(s) AS num
RETURN avg(num) AS average_shares;
+--------------------+
| average_shares |
+--------------------+
| 22.562893081761008 |
+--------------------+
1 row
114 ms
Have any articles been shared multiples times?
MATCH (u:URL)<-[s:SHARED]-()
WITH u, count(s) as shares
RETURN u.url as url, shares ORDER BY shares DESC LIMIT 5;
+-----------------------------------------------------------------------------+
| url | shares |
+-----------------------------------------------------------------------------+
| "http://fiftythree.com/think" | 11 |
| "http://bit.ly/startupbutte" | 9 |
| "http://blog.getprismatic.com/deeper-content-analysis-with-..." | 8 |
| "http://jexp.de/blog/2015/04/neo4j-server-extension-for-sin..." | 7 |
| "https://medium.com/p/aspects-distilled-why-prismatic-s-int..." | 7 |
+-----------------------------------------------------------------------------+
5 rows
760 ms
What are the top keywords across all articles?
MATCH (u:URL)-[r:IS_ABOUT]->(kw:Keyword)
WITH kw, count(r) AS num
RETURN kw.text as keyword, num ORDER BY num DESC LIMIT 10;
+------------------+
| keyword | num |
+------------------+
| "data" | 704 |
| "work" | 424 |
| "way" | 336 |
| "app" | 308 |
| "company" | 304 |
| "world" | 300 |
| "using" | 276 |
| "business" | 250 |
| "medium" | 240 |
| "social" | 236 |
+------------------+
10 rows
794 ms
Note that not all these keywords are perfect. Some seem to be part of a larger phrase. Others, like "medium" were probably taken out of context - medium probably because of the publishing platform Medium. Really we are intested in the topics of the article, not just keywords. An alternative would be to use something like the Prismatic Interest Graph API. But this is a pretty good start.
What are the top keywords for the articles that I've shared?
Looking at the keywords extracted from all the articles you've shared on Twitter can really give an in-depth profile of a person, so I won't call out any of my Twitter friends. Instead, let's look at the top keywords from all articles that I've shared:
MATCH (u:User {username: 'lyonwj'})
MATCH (u)-[:SHARED]-(a:URL)-[r:IS_ABOUT]->(kw:Keyword)
WITH kw, count(r) AS num
RETURN kw.text as keyword, num
ORDER BY num DESC LIMIT 25;
+---------------------+
| keyword | num |
+---------------------+
| "startup" | 8 |
| "youre" | 8 |
| "data" | 7 |
| "startups" | 6 |
| "world" | 6 |
| "graph" | 6 |
| "market" | 5 |
| "technology" | 5 |
| "social" | 4 |
| "developers" | 4 |
| "users" | 4 |
| "chile" | 4 |
| "tech" | 3 |
| "understand" | 3 |
| "mobile" | 3 |
| "20" | 3 |
| "going" | 3 |
| "program" | 3 |
| "programming" | 3 |
| "language" | 3 |
| "industry" | 3 |
| "web" | 3 |
| "team" | 3 |
| "app" | 3 |
| "way" | 3 |
+---------------------+
25 rows
138 ms
I'm showing the top 25 here because I think it's interesting to look at the distribution of the top keywords. This is from a total of 564 distinct keywords extracted from the articles I've shared.
Querying For Recommendations#
Now that we've explored the dataset a bit and are familar with Cypher let's generate some article recommendations! There's a lot of great content online about recommender systems - and especially graph based methods so I'm not going to rehash the details too much. Mostly I just want to demonstrate a basic method and show how easy it is to get started using Neo4j. The basic idea here is that we want to use the information about what users have shared as a form of their preferences. From these preferences we want to find content that they might be interested in.
Item-based recommendations
As I mentioned earlier, the purpose of Cypher is to traverse the graph that we have created and stored in Neo4j. But how can we generate personalized recommendations by traversing the graph? What we want to do is find a path from the user we are generating recommendations for (in this case me) through keywords they are interested in and end up on a new piece of content (in this case a URL node in the graph). In essence:
Bob is interested in machine learning. We know this because he tweeted articles about machine learning. Let's find articles about machine learning in the data set and recommend those to him.
The Cypher query for that looks like this (I've broken it up into multiple lines for readability - this is also a good time to reference this optimizing Cypher queries talk):
MATCH (user:User {username: 'lyonwj'})
MATCH (user)-[:SHARED]->(url:URL)
MATCH (url)-[:IS_ABOUT]->(kw:Keyword)<-[:IS_ABOUT]-(a:URL)
RETURN DISTINCT a.url LIMIT 10;
+------------------------------------------------------------------------------+
| a.url |
+------------------------------------------------------------------------------+
| "http://www.bozemandailychronicle.com/business/profile/blackstone-launch..." |
| "http://mtstandard.com/news/state-and-regional/montana-ranked-th-best-st..." |
| "http://lnkd.in/bWEjg4v" |
| "http://bloom.bg/1qkrBHQ" |
| "http://www.theguardian.com/lifeandstyle/2015/may/03/owning-trailer-park..." |
| "http://ow.ly/DYAet" |
| "http://shar.es/MrXme" |
| "http://bit.ly/zGDDFR" |
| "http://projects.propublica.org/pactrack/contributions/tree" |
| "http://www.fastcoexist.com/3045836/heres-what-happened-when-a-neighbor..." |
+------------------------------------------------------------------------------+
10 rows
67 ms
OK - so we have some urls. In fact, without the LIMIT statement we have over 5000 urls to recommend. We need some way to score these recommendations so we can only recommend the urls the user is most likely to be interested in.
If we look at the path from me to the first recommended article we see this:
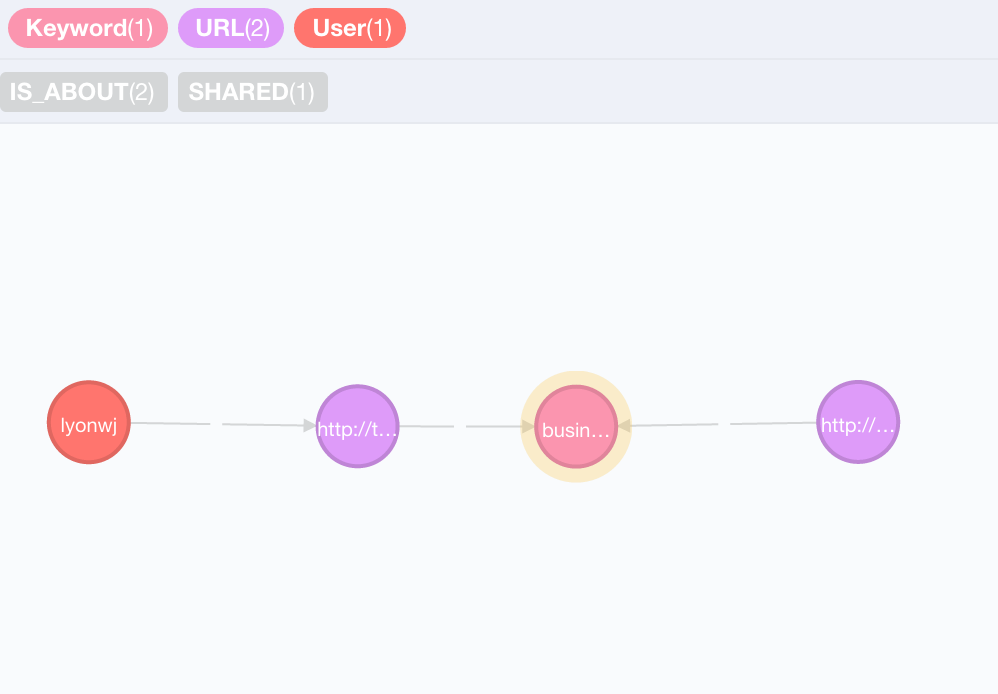
I tweeted an article about business, so I was recommended another article about business. OK that seems somewhat relevant, but a bit generic perhaps. Can we include more information about my preferences to make the recommendation a bit more relevant? If we expand the :IS_ABOUT relationships for each of the articles in that path we see that there are many more keywords for each article. Each article has about a dozen relationships, but the only overlapping keyword is "business":
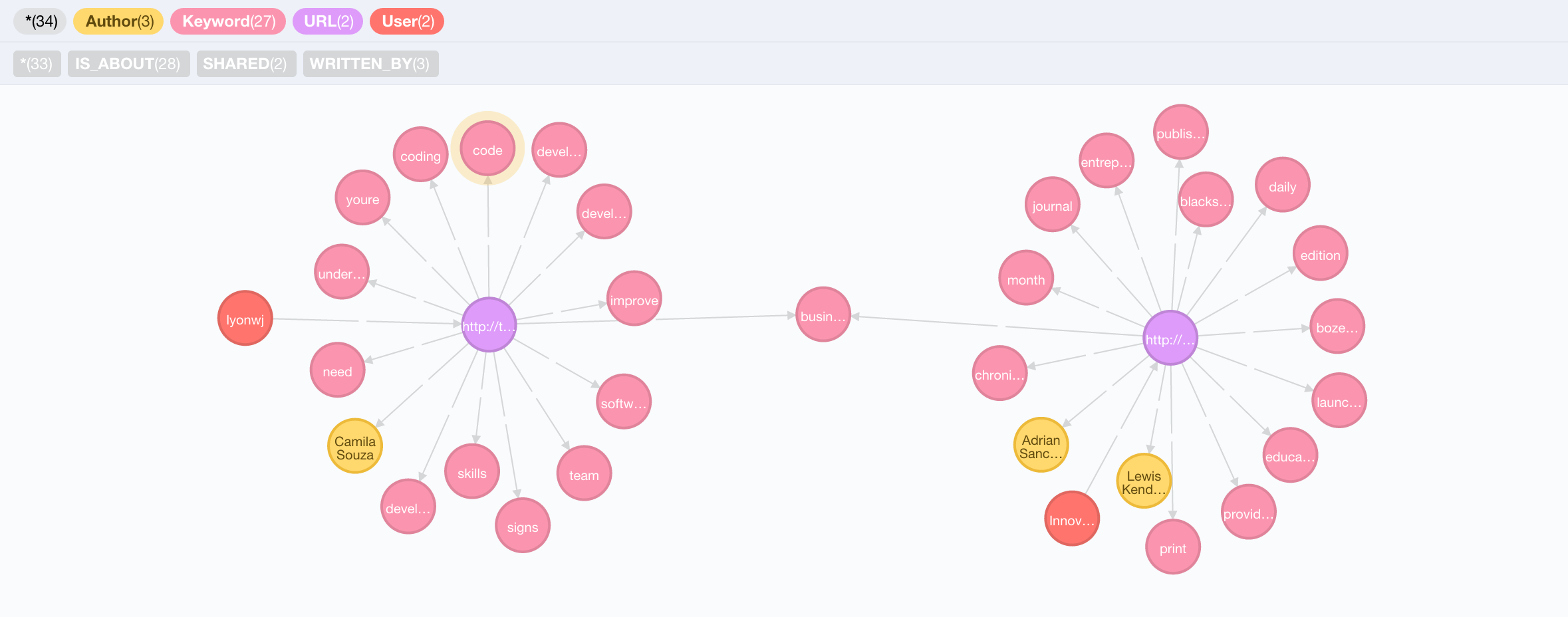
Of those dozen keywords from the recommended article, how many overlap with keywords that we've identified as interesting to me?
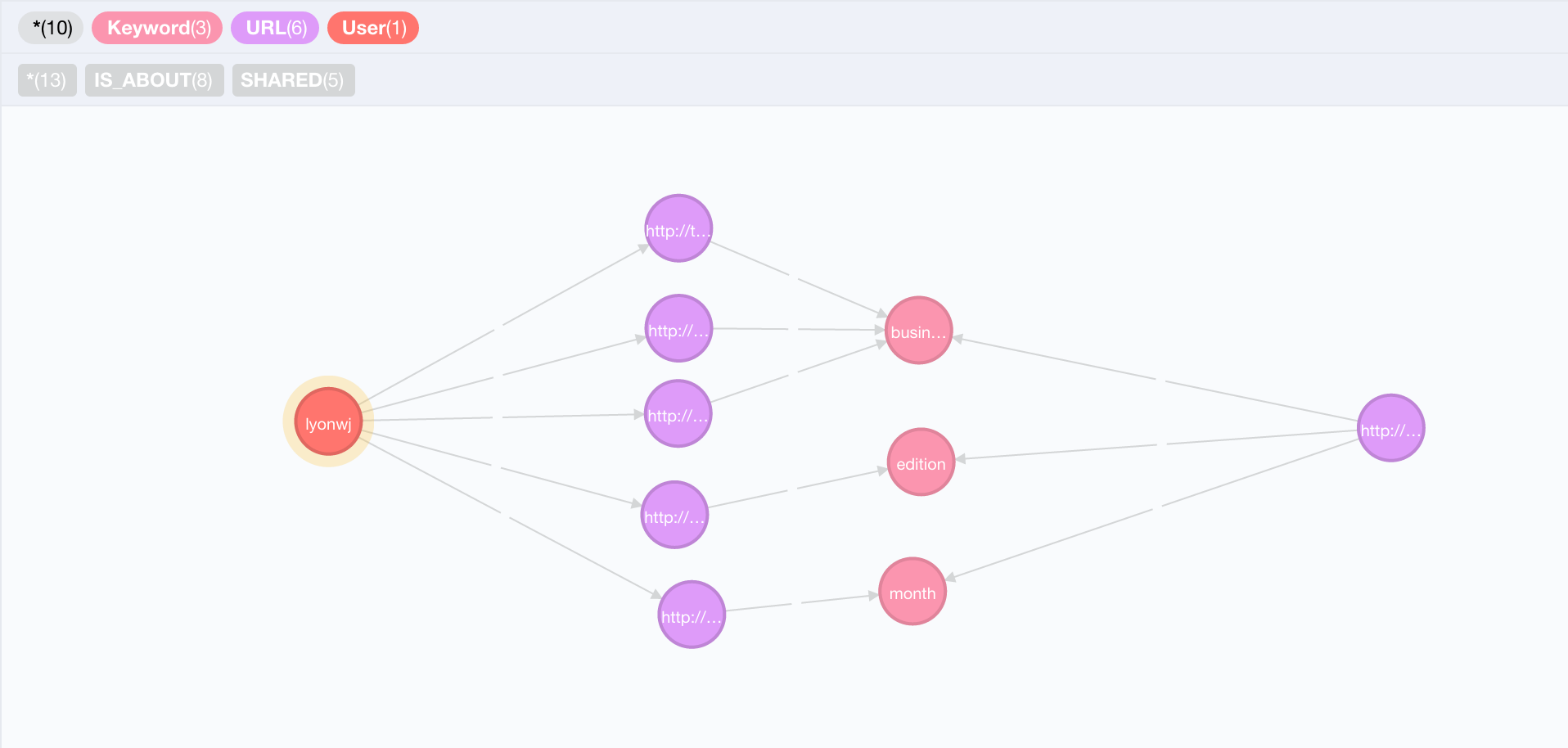
And we can see there are three overlapping keywords: "business", "edition" and "month". We can also see there are multiple paths from the User node to the recommended article, 5 specifcally. Each path goes through an article that I've shared, into a keyword node that is shared by the recommended article. We can use the number of paths as a score for the relevance of the recommendation. The more paths we have between the User and the recommended article, the more relevant the article is likely to be and the stronger the recommendation. Here's how we can use the number of paths as a score for recommenations in Cypher:
MATCH (u:User {username: 'lyonwj'})-[:SHARED]->(url:URL)
MATCH (url)-[r:IS_ABOUT]->(kw:Keyword)<-[r2:IS_ABOUT]-(u2:URL)
WHERE NOT (u)-[:SHARED]->(u2)
WITH u2.url as article, count(r2) as score
RETURN article, score ORDER BY score DESC LIMIT 10;
+------------------------------------------------------------------------------+
| article | score |
+------------------------------------------------------------------------------+
| "http://bit.ly/1cWjwrS" | 56 |
| "http://blog.graphenedb.com/blog/2015/01/16/neo-technology-just..." | 52 |
| "http://on.tcrn.ch/l/lonK" | 46 |
| "http://www.nytimes.com/2014/12/03/business/economy/income-gap-..." | 44 |
| "http://genius.com/B-horowitz-the-hard-thing-about-hard-things-..." | 44 |
| "http://blog.goomzee.com/2014/09/10/goomzee-black-knight-clarit..." | 42 |
| "http://www.defmacro.org/2015/02/25/startup-ideas.html" | 37 |
| "https://linkurio.us/rise-full-stack-graph-startup/" | 36 |
| "http://ow.ly/zoBOE" | 36 |
| "http://linkurio.us/jobs/" | 35 |
+------------------------------------------------------------------------------+
10 rows
347 ms
Now we have a score associated with each url so we can recommend only the top x articles or set some threshold for how relevant we think the article is before we recommend it. Note that I also added this statement to our Cypher query: WHERE NOT (u)-[:SHARED]->(u2). We want to be sure to exclude any articles that I've shared myself, as articles that I've obviously already read are not relevant recommendations for content discovery.
Let's look at all the paths for the top scored recommendation:
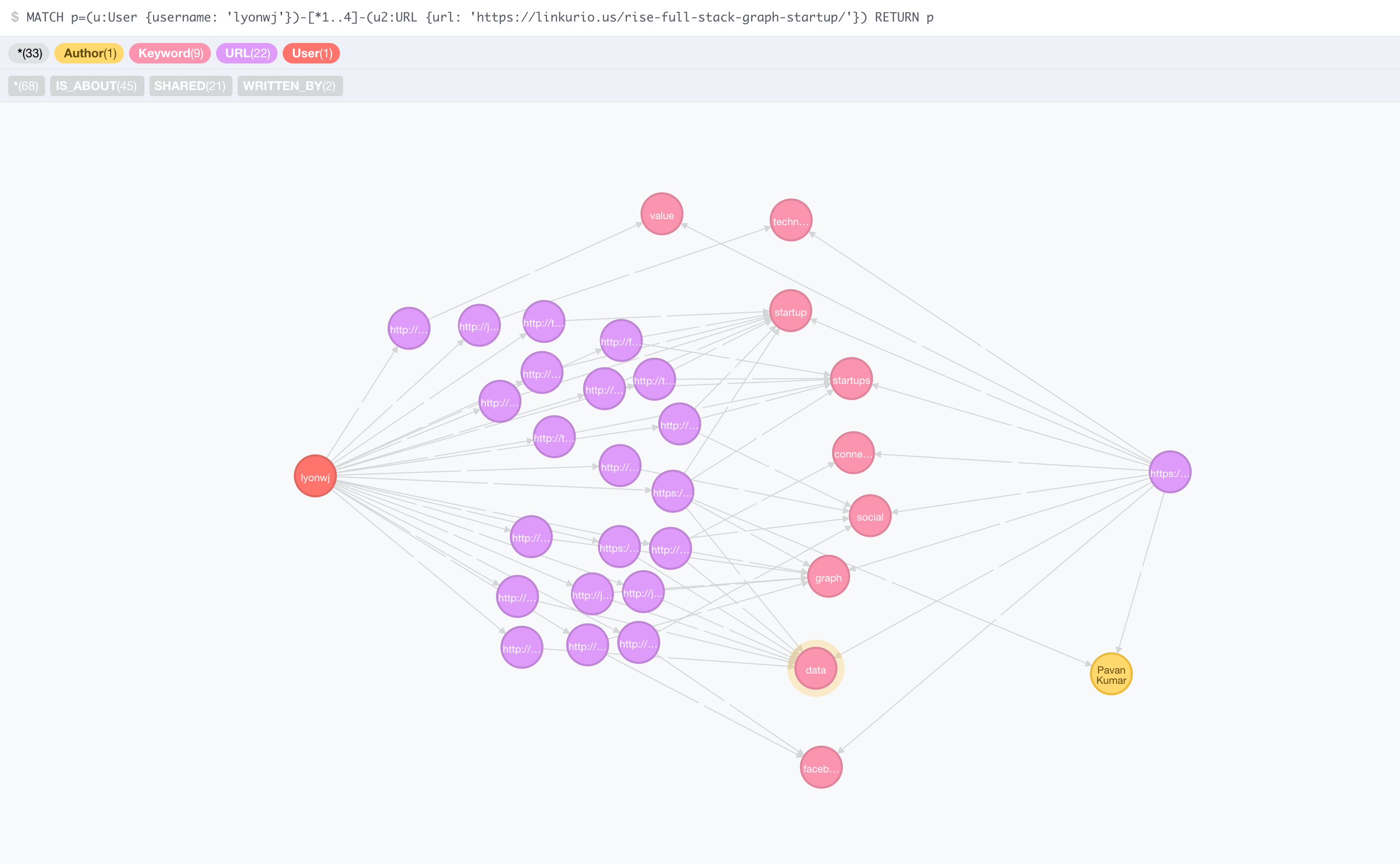
Here we can see all the paths (through 9 distinct keywords) to one of the top rated recommended articles. One of the articles I shared even shares an author with this article!
Further research#
There's a lot more we could do with this project. One suggestion I made previously was using a more advanced method for obtaining article topics (such as the Prismatic Interest Graph API). Here are some other things we might want to explore:
- Location - How can we include location in our method for generating recommendations? Will user's be more interested in articles shared by those close to them?
- Evaluation - How do we know if the recommendations we are generating are relevant? Are the users actually interested in any of the articles we are recommending?
- Multiple edge types - Remember above when we saw that we had an overlapping Author? We didn't look at it in this article, but we can certainly make use of those additional relationship types for boosting our recommendation relevance.
Stay Updated
Get notified about new posts and videos