Congressional PageRank - Analyzing US Congress With Neo4j and Apache Spark
William Lyon / October 11, 2015
12 min read •
As we saw previously, legis-graph is an open source software project that imports US Congressional data from Govtrack into the Neo4j graph database. This post shows how we can apply graph analytics to US Congressional data to find influential legislators in Congress. Using the Mazerunner open source graph analytics project we are able to use Apache Spark GraphX alongside Neo4j to run the PageRank algorithm on a collaboration graph of US Congress.
While Neo4j is a powerful graph database that allows for efficient OLTP queries and graph traversals using the Cypher query language, it is not optimized for global graph algorithms, such as PageRank. Apache Spark is a distributed in-memory large-scale data processing engine with a graph processing framework called GraphX. GraphX with Apache Spark is very efficient at performing global graph operations, like the PageRank algorithm. By using Spark alongside Neo4j we can enhance our analysis of US Congress using legis-graph.
Neo4j + Apache Spark: Overview of the Mazeruner project#
Mazerunner is a powerful open source graph analytics project that enables us to run Apache Spark GraphX jobs on a subgraph exported from Neo4j. Mazerunner makes use of Docker to allow for easy deployment. From the Mazerunner GitHub README:
This docker image adds high-performance graph analytics to a Neo4j graph database. This image deploys a container with Apache Spark and uses GraphX to perform ETL graph analysis on subgraphs exported from Neo4j. The results of the analysis are applied back to the data in the Neo4j database.
Mazerunner was created by Kenny Bastani who has written some great posts about using Mazerunner for graph analytics with Neo4j.
Using docker compose#
We'll use Docker to run Mazerunner so be sure to install Docker before moving on. Docker will allow us to easily deploy Hadoop HDFS, Neo4j and Apache Spark. We'll use docker compose to manage our containers and define the port bindings. To start, we'll create a yaml file that specifies the containers we'd like to spin up, how they should be linked to each other and which ports should be exposed:
hdfs:
image: sequenceiq/hadoop-docker:2.4.1
command: /etc/bootstrap.sh -d -bash
mazerunner:
image: kbastani/neo4j-graph-analytics:latest
links:
- hdfs
graphdb:
image: kbastani/docker-neo4j:latest
ports:
- "7474:7474"
- "1337:1337"
volumes:
- /opt/data
links:
- mazerunner
- hdfs
See this GitHub page for more information about running Mazerunner with Docker compose.
The yaml file defines the three containers we'll be using (Hadoop HDFS, Mazerunner service, and Neo4j), how they should be linked and what ports should be exposed so that we can access Neo4j. We can start this configuration with a single command:
docker-compose up
We now have Hadoop HDFS, an empty Neo4j instance and Mazerunner service running in separate containers, but linked together (with some docker magic...). We can connect to Neo4j easily since the Neo4j ports are exposed. Since I'm using docker on a Mac, there is actually a docker virtual machine running locally. To connect to Neo4j I can use the IP address of this VM. The default docker VM IP address is 192.168.99.100 but we can confirm with the docker-machine inspect command:
lyonwjs-MacBook-Pro-2:~ lyonwj$ docker-machine inspect default | grep IPAddress
"IPAddress": "192.168.99.100",
We can now connect to the Neo4j Browser at http://192.168.99.100:7474/browser/ to verify that Neo4j is running and there is no data in the database.
Now we need some data...
Importing legis-graph#
If you haven't read my previous post about the legis-graph project you should at least skim it over to see the data model we are working with and some of the queries that are possible.
Now that we have Neo4j running we can import legis-graph into the database, following the steps described here. The steps involve fetching GovTrack data with rsync, using Python scripts to parse the JSON, YAML and CSV files provided by GovTrack into a series of CSV files that we can then import directly into Neo4j using Cypher scripts. The screencast below shows the exact commands so you can follow along. It's worth noting that we're using neo4j-shell to run the Cypher import scripts instead of the Neo4j Browser. To access the neo4j-shell in our Docker container we can first get a bash prompt with the command
docker exec -it CONTAINER_ID_HERE bash
where CONTAINER_ID_HERE is the id of the container running Neo4j, which we can find with the docker ps command. See the first part of the gif below. Once we have access to the shell in the container the steps to import legis-graph are identical to the those described in the project readme).
Adding INFLUENCED_BY relationship#
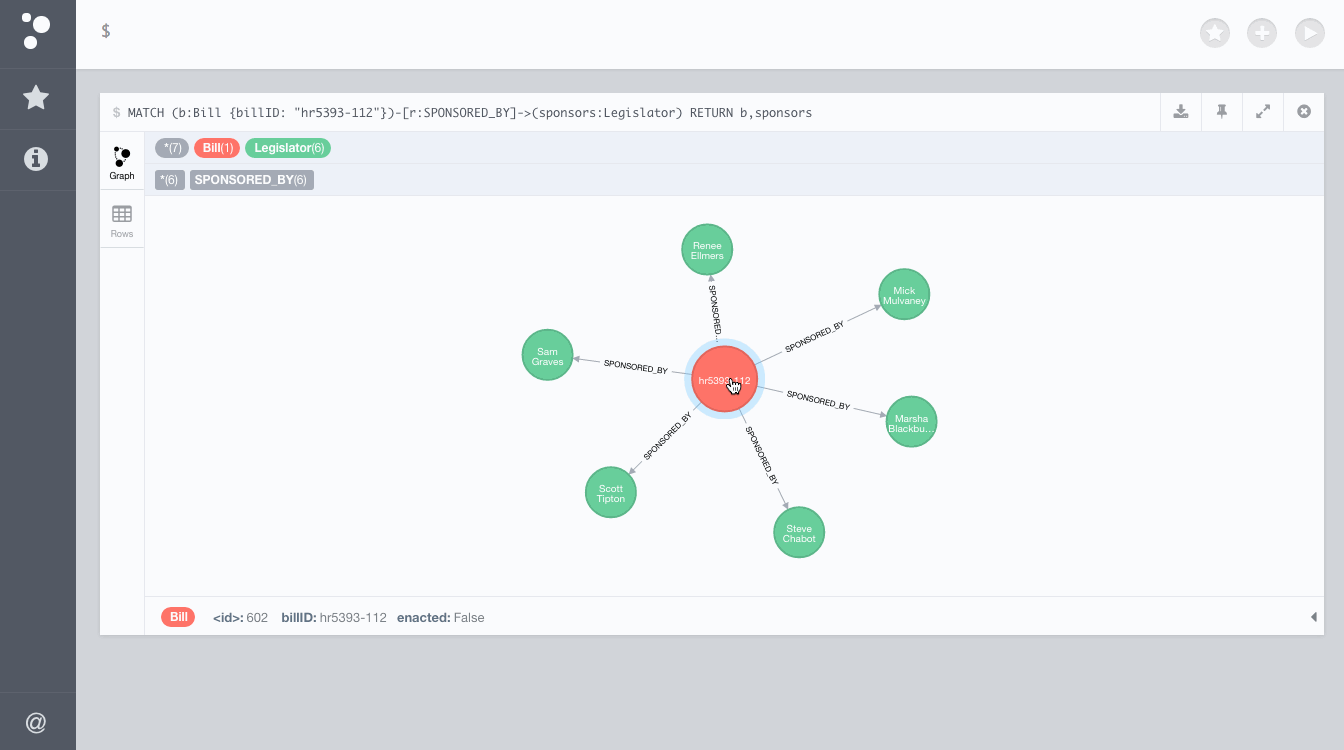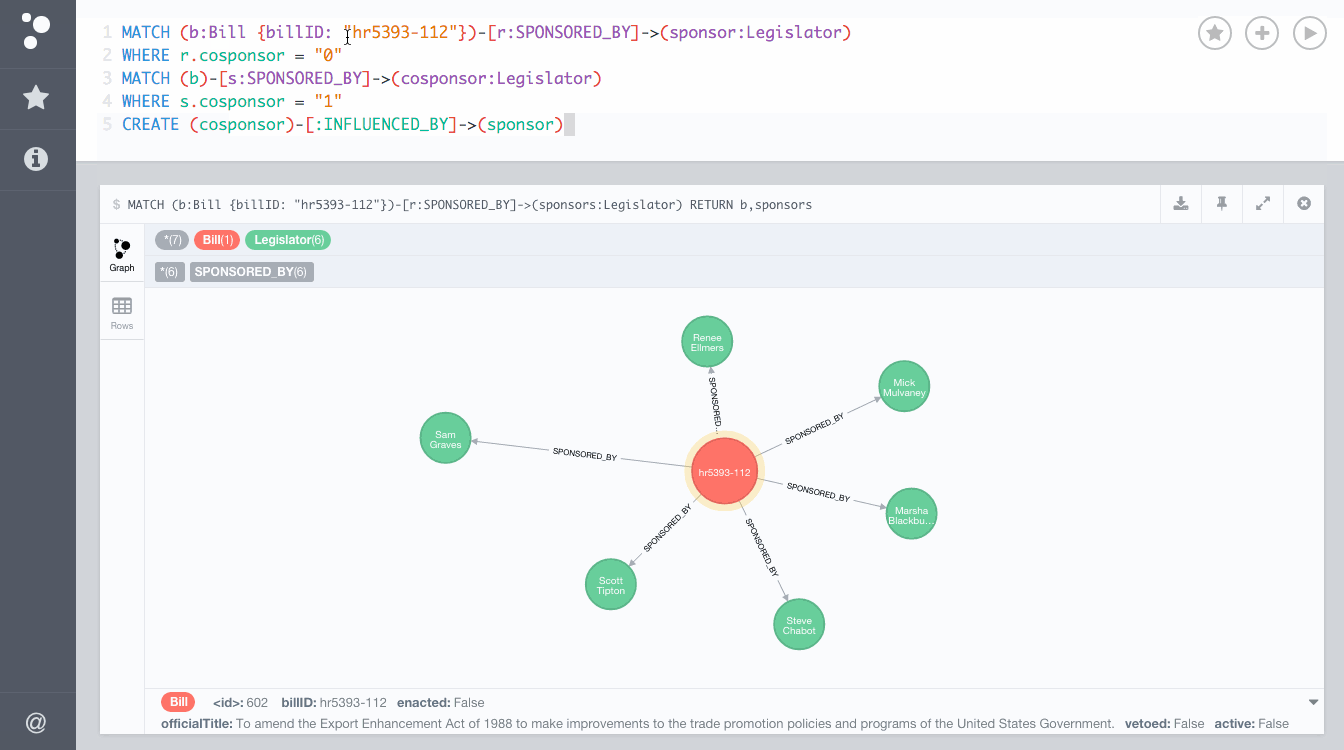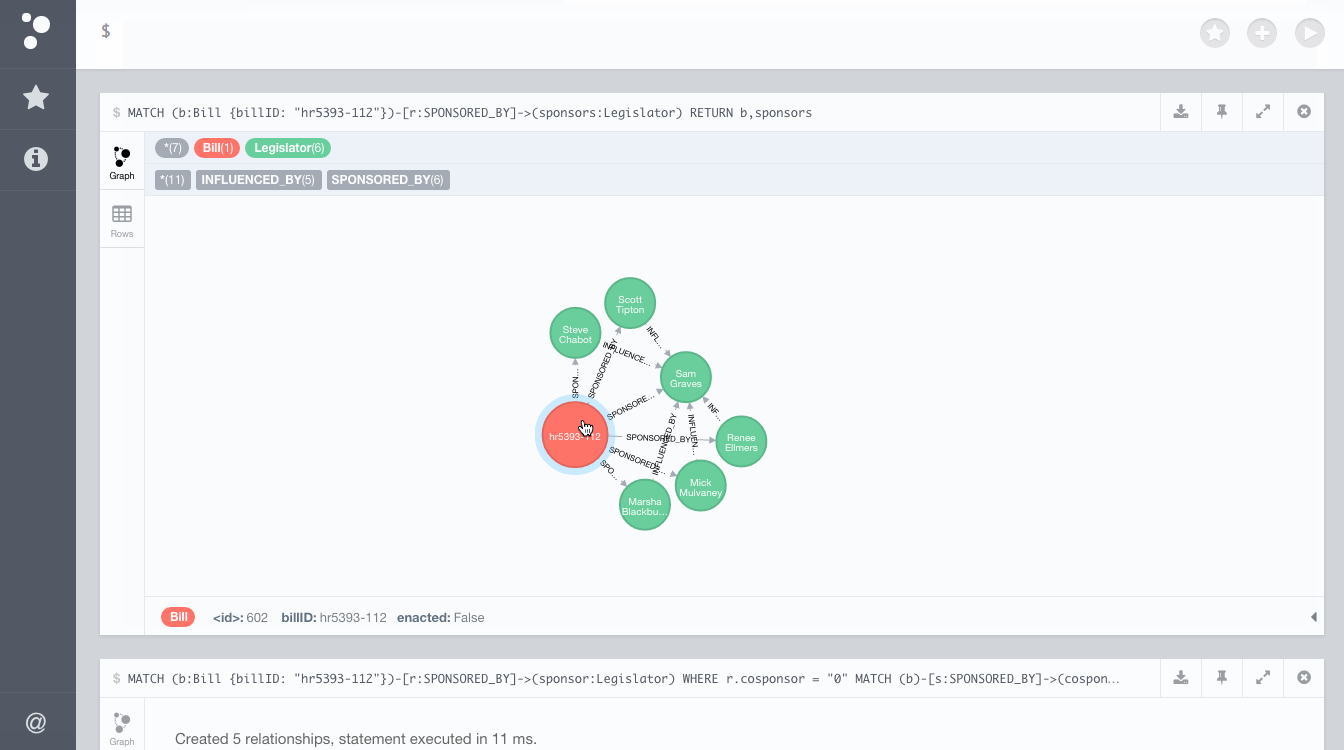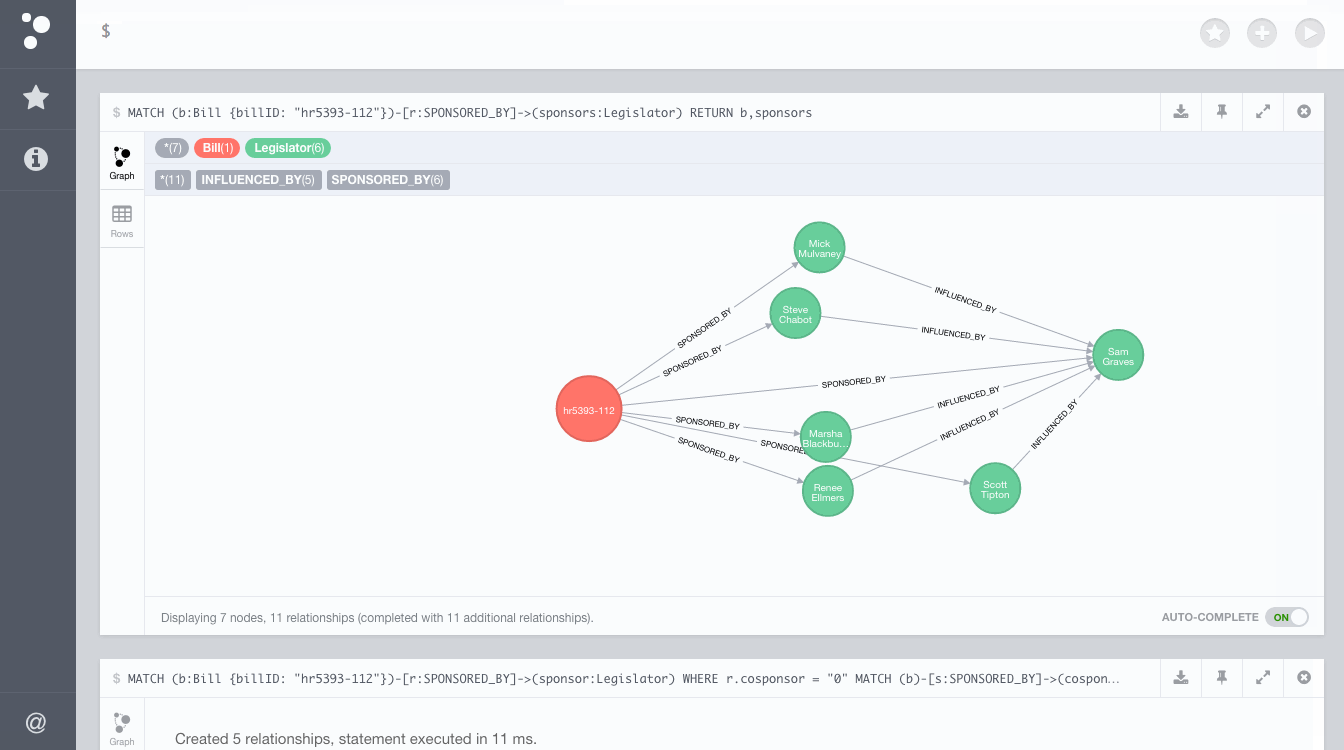
INFLUENCED_BY relationship#Once the import scripts have finished running we have data describing every US Congress Legislator, Bill and Committee for a given Congressional session (the results below are based on data from the 114th Congressional session, the most current session) in a Neo4j property graph. Our data model looks like this:
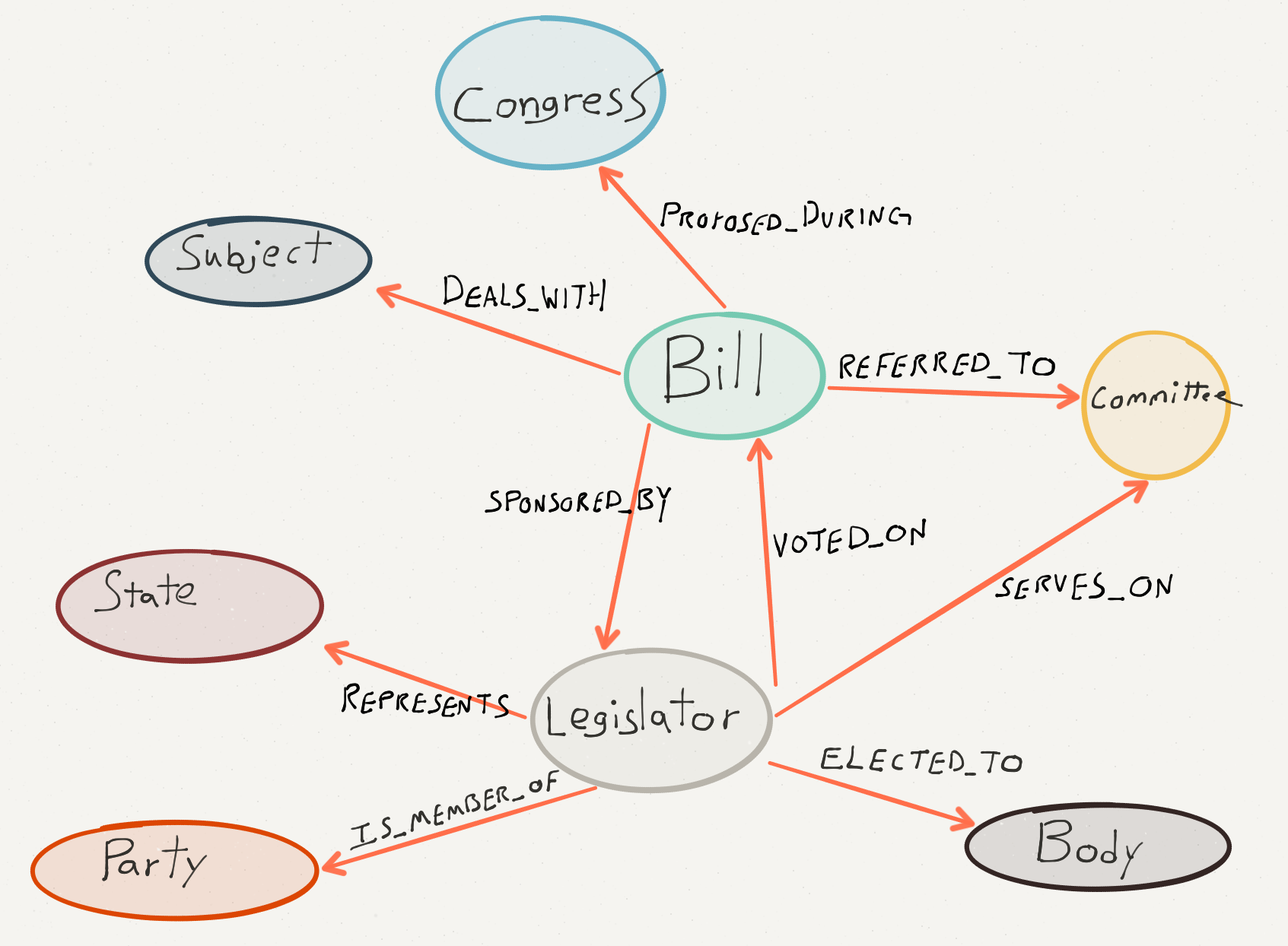
In the data model we can see a relationship between our Legislator nodes and Bill nodes called SPONSORED_BY. From our memory of Schoolhouse Rock we know that every Bill has an initial Sponsor who introduces the Bill and several Cosponsors who support the Bill as well. In a political sense we can think of the Sponsor as influencing the Cosponsors to support the Bill. Although it's not explicitly modeled in our graph we can use this measure of influence to identify influential Legislators.
We will start by finding these implicit relationships in the Congressional collaboration graph and creating explicit INFLUENCED_BY relationships. Anytime that a Bill was introduced by a Sponsor and then supported by Cosponsors, we will model that influence in our graph by creating an INFLUENCED_BY relationship from each Cosponsor to the Sponsor. For example, let's consider a specific Bill, HR5393, which was introduced and sponsored in the House by Representative Sam Graves. This Bill was then cosponsored by Representatives Mick Mulvaney, Steve Chabot, Marsha Blackburn, and Scott Tipton. We can observe that Rep Sam Graves demonstrated political leadership and influence over the cosponsors of this Bill by garnering its support, so we create an INFLUENCED_BY relationship from each cosponsor to Sam Graves in the graph to represent this political influence.
This Cypher query will update our graph and create these new INFLUENCED_BY relationships for all Bills:
MATCH (b:Bill)-[r:SPONSORED_BY]->(sponsor:Legislator)
WHERE r.cosponsor = "0"
MATCH (b)-[s:SPONSORED_BY]->(cosponsor:Legislator)
WHERE s.cosponsor = "1"
CREATE (cosponsor)-[:INFLUENCED_BY]->(sponsor)
Running PageRank on Legislators#
We can use these new INFLUENCED_BY relationships as inputs for the PageRank algorithm to find influential legislators. PageRank is an algorithm initially used by Google to measure the importance of webpages for Google Search. The same algorithm can be applied to many different types of networks to find significant nodes in the network. In our case we will be using PageRank to measure the political influence of legislators based on Bill sponsorship and cosponsorship.
Note that this type of analysis is similar to the GovTrack leadership analysis as explained in this presentation. Both are based on the PageRank algorithm and the results are roughly similar.
Running PageRank with Mazerunner#
When we started our Docker containers earlier, one of those containers contained Mazerunner, a powerful tool for running Apache Spark GraphX jobs on HDFS with data from Neo4j. We can start a job in Mazerunner by making a simple GET request to Neo4j. The GET request only needs to specify the type of analysis we want to perform (in this case PageRank), and the relationship type on which we want to perform the analysis (INFLUENCED_BY in this case). Mazerunner will then take care of exporting the relevant subgraph to Spark, running the Spark GraphX job and then writing the results back to Neo4j. We can trigger this analysis from within the Neo4j browser with this command:
:GET /service/mazerunner/analysis/pagerank/INFLUENCED_BY
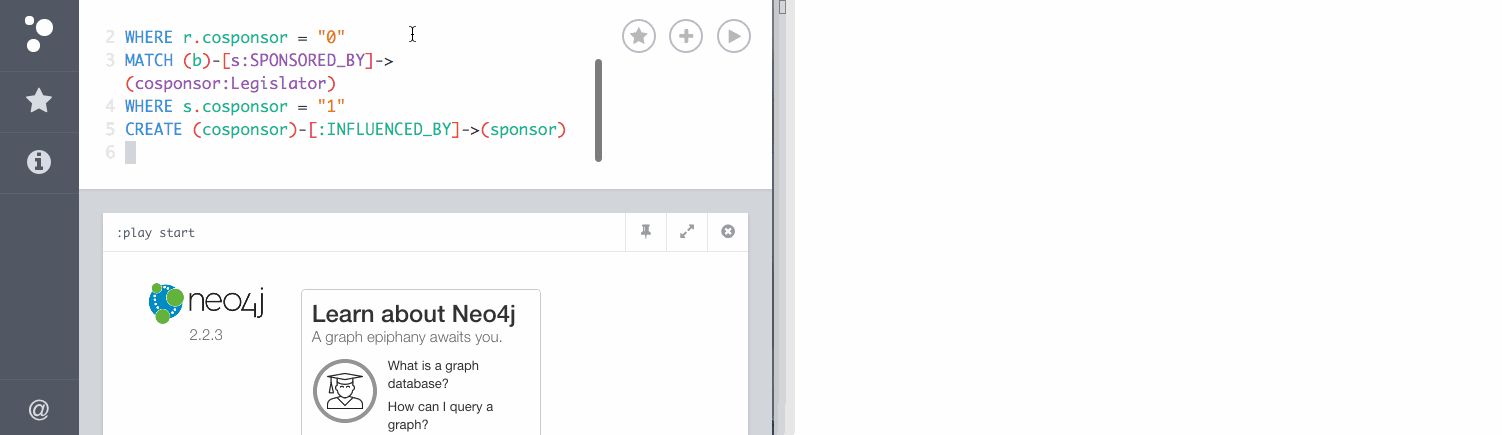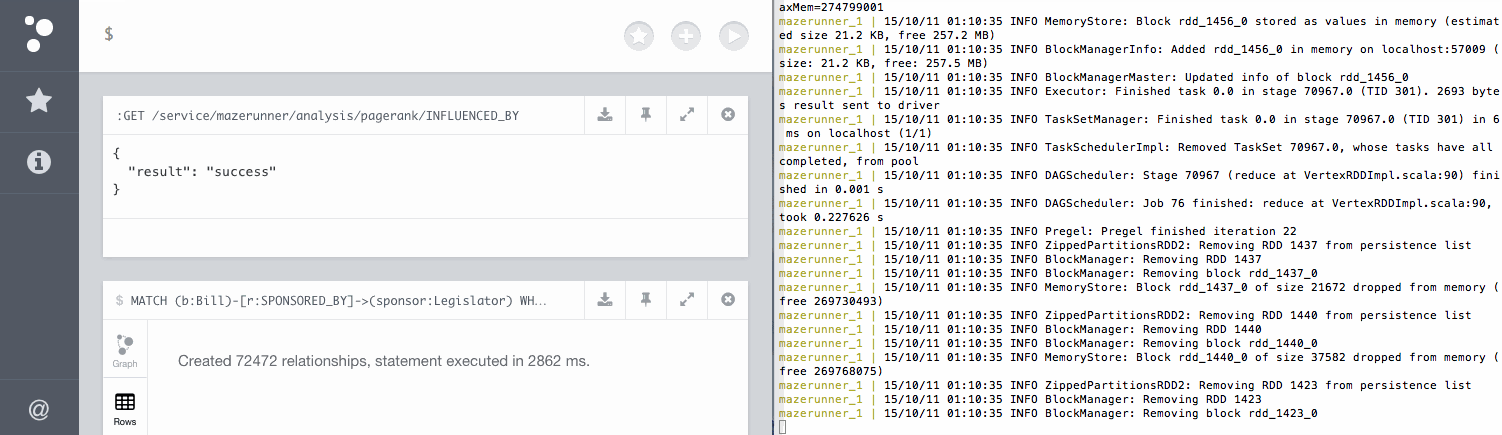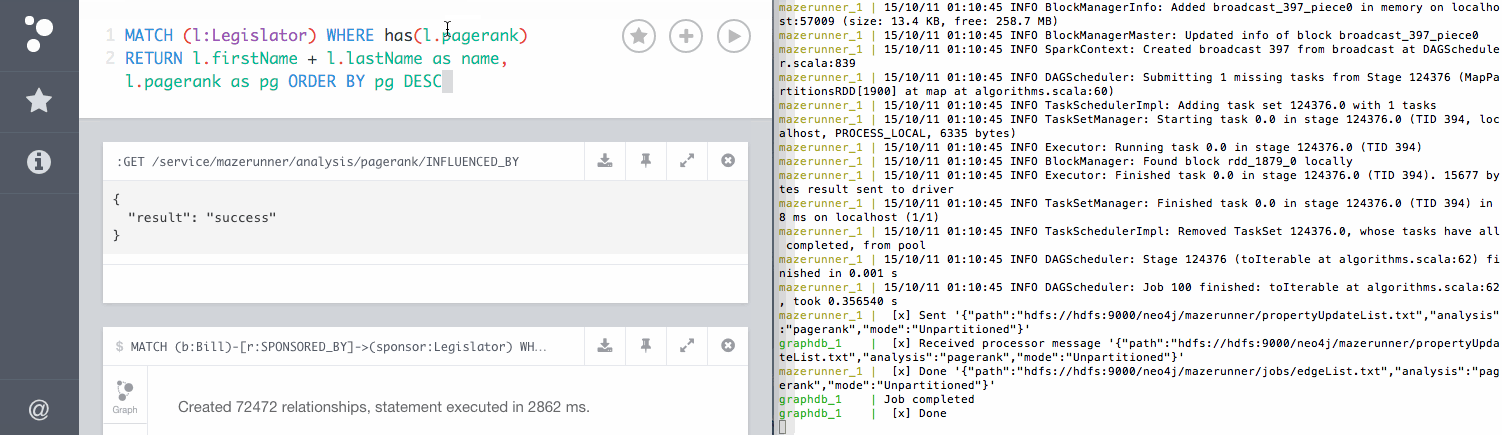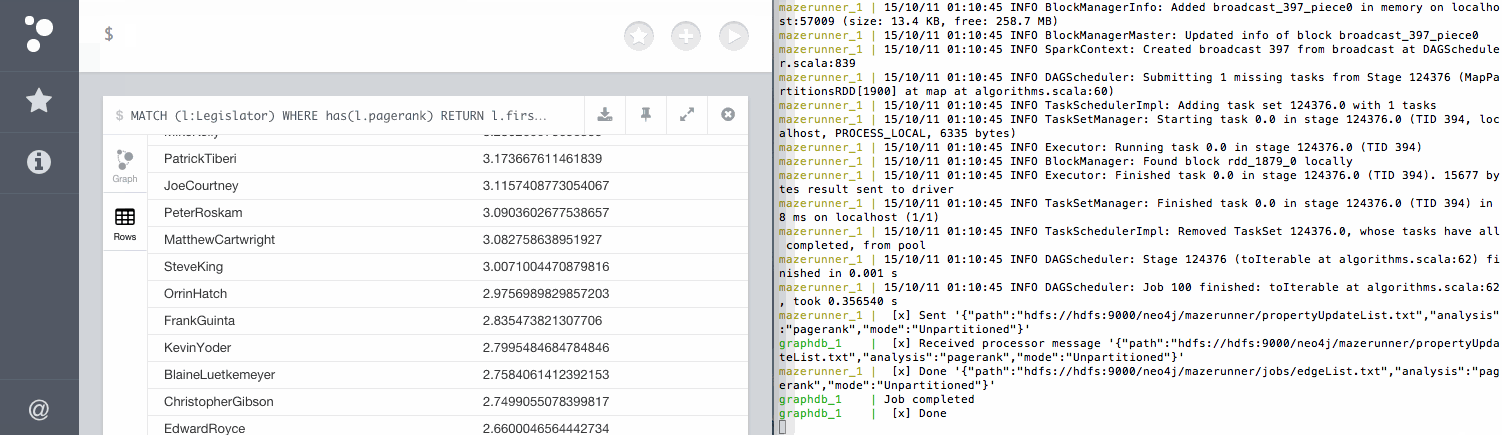
Once the PageRank analysis job is complete, each Legislator node will be updated with a new pagerank property that contains the value of that Legislator's PageRank score based on the INFLUENCED_BY relationships. We can use this score as a proxy for political influence in Congress. Since this PageRank score was written back to Neo4j we can use Cypher queries to now take into account a Legislator's political influence when querying the graph. In the next section we'll answer some interesting questions about finding influencers in Congress using Cypher and our new Congressional PageRank score.
Finding influential legislators#
Most influential Senators#
MATCH (l:Legislator) WHERE has(l.pagerank) WITH l, l.pagerank as pg
MATCH (l)-[:ELECTED_TO]->(b:Body {type: "Senate"})
RETURN l.firstName + l.lastName as name, pg ORDER BY pg DESC LIMIT 10;
+-----------------------------------------+
| name | pg |
+-----------------------------------------+
| "Orrin Hatch" | 2.9756989829857203 |
| "Charles Grassley" | 2.6139548199234857 |
| "Benjamin Cardin" | 2.1132989694887456 |
| "John Thune" | 2.0930332521393904 |
| "Mike Lee" | 2.0406616669993336 |
| "Lamar Alexander" | 2.031176645832514 |
| "Jerry Moran" | 1.9622461537176095 |
| "John Cornyn" | 1.956690813571645 |
| "John Barrasso" | 1.924180343470944 |
| "Jeff Flake" | 1.8889703078024018 |
+-----------------------------------------+
10 rows
121 ms
Most influential in House of Representatives#
MATCH (l:Legislator) WHERE has(l.pagerank) WITH l, l.pagerank as pg
MATCH (l)-[:ELECTED_TO]->(b:Body {type: "House"})
RETURN l.firstName + " " + l.lastName as name, pg ORDER BY pg DESC LIMIT 10;
+------------------------------------------+
| name | pg |
+------------------------------------------+
| "Diane Black" | 8.58655429827745 |
| "Brett Guthrie" | 6.062435816533887 |
| "Bob Goodlatte" | 5.77444037360594 |
| "Erik Paulsen" | 5.769744558672802 |
| "Sam Johnson" | 5.51484568055709 |
| "Charles Boustany" | 5.225312360342051 |
| "Carolyn Maloney" | 4.879633494250425 |
| "Christopher Smith" | 4.799080848575352 |
| "Kevin Brady" | 4.5629395513518265 |
| "Paul Gosar" | 4.005903699546033 |
+------------------------------------------+
10 rows
63 ms
Most influential Democrats in the House of Representatives#
MATCH (l:Legislator) WHERE has(l.pagerank) WITH l, l.pagerank as pg
MATCH (l)-[:ELECTED_TO]->(b:Body {type: "House"})
MATCH (l)-[:IS_MEMBER_OF]->(p:Party {name: "Democrat"})
RETURN l.firstName + " " + l.lastName as name, pg ORDER BY pg DESC LIMIT 10;
+-------------------------------------------+
| name | pg |
+-------------------------------------------+
| "Carolyn Maloney" | 4.879633494250425 |
| "Rosa DeLauro" | 3.9910225707498417 |
| "Joe Courtney" | 3.1157408773054067 |
| "Matthew Cartwright" | 3.082758638951927 |
| "Terri Sewell" | 2.460045410055251 |
| "Jackie Speier" | 2.184626502764663 |
| "Maxine Waters" | 2.074914490498521 |
| "David Cicilline" | 1.927110056774834 |
| "Henry Johnson" | 1.8882492772785748 |
| "Robert Scott" | 1.7769840317110424 |
+-------------------------------------------+
10 rows
62 ms
Most influential for specific subjects#
Here is where things get interesting and we start really leveraging the power of the graph. Simply by traversing the graph, we can find Legislators who have significant influence in Congress over specific subjects given the Commitees on which they serve and the types of Bills referred to those Committees.
Hong Kong
Let's take Hong Kong as a random example. Who are the Legislators with the highest level of influence (as measured by our Congressional PageRank score) who have influence over the subject of "Hong Kong", based on the Commitees on which they serve?
MATCH (l:Legislator) WHERE has(l.pagerank) WITH l, l.pagerank as pg
MATCH (l)-[r:SERVES_ON]->(c:Committee)
MATCH (c)<-[:REFERRED_TO]-(:Bill)-[d:DEALS_WITH]->(s:Subject)
WHERE s.title = "Hong Kong"
MATCH (l)-[:IS_MEMBER_OF]->(p:Party)
WITH l.firstName + " " + l.lastName as name, pg, c.name AS committee,
r.rank as rank, p.name as party
RETURN name, pg, committee, rank, party ORDER BY pg DESC LIMIT 10;
+-------------------------------------------------------------------------------------+
| name | pg | committee | rank | party |
+-------------------------------------------------------------------------------------+
| "Christopher Smith" | 4.79 | "House Committee on Foreign Af" | "2" | "Republican" |
| "Edward Royce" | 2.66 | "House Committee on Foreign Af" | "1" | "Republican" |
| "Reid Ribble" | 2.36 | "House Committee on Foreign Af" | "22" | "Republican" |
| "Ted Poe" | 2.30 | "House Committee on Foreign Af" | "8" | "Republican" |
| "Matt Salmon" | 2.12 | "House Committee on Foreign Af" | "9" | "Republican" |
| "David Cicilline" | 1.92 | "House Committee on Foreign Af" | "10" | "Democrat" |
| "Ted Yoho" | 1.71 | "House Committee on Foreign Af" | "19" | "Republican" |
| "Joe Wilson" | 1.60 | "House Committee on Foreign Af" | "6" | "Republican" |
| "Steve Chabot" | 1.55 | "House Committee on Foreign Af" | "5" | "Republican" |
| "Tom Marino" | 1.51 | "House Committee on Foreign Af" | "11" | "Republican" |
+-------------------------------------------------------------------------------------+
10 rows
79 ms
Here we can see Legislators who have influence over the subject "Hong Kong" through their membership on the House Committee on Foreign Affairs, sorted by PageRank. We should also take into account their rank on the Committee, a higher rank being another sign of a higher level of influence. We can run this query for any subject in our graph, just change the s.title = xxx parameter and find Congressional influencers!
Multiple dimensions of influences
Of course a Legislator might serve on multiple Committees that have jurisdiction over a certain subject. Here we examine Legislators who have influence over the subject "News media and reporting" and order the results by the number of Committees on which they serve that have jurisdiction over the subject.
MATCH (l:Legislator) WHERE has(l.pagerank) WITH l, l.pagerank as pg
MATCH (l)-[r:SERVES_ON]->(c:Committee)<-[:REFERRED_TO]-(:Bill)-[d:DEALS_WITH]->(s:Subject)
WHERE s.title = "News media and reporting"
MATCH (l)-[:IS_MEMBER_OF]->(p:Party)
WITH l.firstName + " " + l.lastName as name, pg, count(d) as num, p.name as party, c, r
WITH collect({committee:c.name, rank:r.rank}) AS committees, name, pg, num, party
RETURN name, pg, committees, num, party ORDER BY size(committees) DESC LIMIT 10;

To take these multiple levels of influence into account we could create some sort of composite index of influence and order our results by that index, but I'll leave that as an exercise for the reader...
If you are a social scientist, or anyone interested in working with Congressional data in legis-graph please let me know your use-case and how I can help!
Subscribe To Will's Newsletter
Want to know when the next blog post or video is published? Subscribe now!