Give Your Vercel Eve Agent a Memory: Building a Context Graph with NAMS
William Lyon
June 24, 2026
26 min read
Vercel recently shipped Eve, a framework with a tagline that landed immediately for me: "Next.js for agents."
You write a directory of files - a Markdown system prompt, a one-line model config, and tools as individual TypeScript files then Eve compiles all of that into a durable agent running on Vercel Functions. Sessions survive crashes and deploys, streaming and sandboxing are handled for you, and every run shows up in an observability dashboard. It takes care of an enormous amount of plumbing.
I'd been wanting to build an AI-assisted National Parks trip planner for a while, so when Eve came out I thought it would be fun to build it on Eve. I quickly ran into a problem though: Eve gives your agent a durable runtime, but it doesn't give your agent a durable mind. Out of the box my carefully-engineered park ranger greeted a returning user like a complete stranger, every single time.
In this post we'll take a look at how to close that gap with three pieces working together: Eve as the runtime, the Neo4j Agent Memory Service (NAMS) as the memory layer, and Neo4j itself as the substrate that makes that memory queryable. We'll wire NAMS into an Eve agent to give it persistent memory, and we'll see why backing that memory with a graph (rather than a pile of embeddings) is what makes the agent feel like it actually knows you. I'll use the app I built - TrailGraph, an AI-assisted U.S. National Parks trip planner - as our running example throughout.
This post started as more of a case study but ended up fairly hands-on - the code snippets are real and mostly copy-pasteable - but at each step I've also pulled out the reusable pattern so you can drop it into your own Eve project.
What you'll learn: how to wrap a memory service behind a clean interface, persist conversations reliably, bind user identity safely, and - the fun part - store an agent's memory as a graph that lives right next to your application data. Who this is for: developers comfortable with TypeScript who've spent a little time with Eve, Neo4j, and Cypher (and ideally Better Auth). You don't need to be an expert in any of them to follow along.

One term I'll lean on throughout: a context graph is just your agent's memory modeled as a graph - the user, the things they care about, and the relationships between them - rather than as a flat pile of text snippets.
What Eve Gives You (And What It Doesn't)#
An Eve agent really is just a directory of files. Here's the entire model config for TrailGraph's ranger:
// agent/agent.ts
import { defineAgent } from 'eve';
export default defineAgent({
model: process.env.AGENT_MODEL ?? 'anthropic/claude-sonnet-4.6',
});
Tools are individual files that call defineTool, and the filename becomes the tool name the model sees. Here's a real one from TrailGraph - parks_near finds parks within a radius using a Neo4j point index:
// agent/tools/parks_near.ts
export default defineTool({
description: 'Find national parks within a radius of a location, optionally filtered by activity.',
inputSchema: z.object({
latitude: z.number(),
longitude: z.number(),
radiusMiles: z.number().max(500).default(150),
activity: z.string().optional(),
}),
async execute(input, ctx) {
// ordinary TypeScript: run a Neo4j point-distance query,
// return a { kind, data } park-card payload
},
});
The description and inputSchema are the Eve-specific part - the contract the model sees when it decides whether to call a tool. The execute body is just TypeScript; here it's a Cypher point-distance query (the full version is in the repo) returning a { kind, data } payload the UI renders as park cards.
The system prompt is just Markdown in instructions.md, which is where the ranger's personality and tool-use policy live:
<!-- agent/instructions.md -->
You are **Ranger**, TrailGraph's National Parks trip-planning assistant.
## How to work a turn
1. Call `recall_user_context` early to load the user's saved preferences and prior trips.
2. Use domain tools (`search_parks`, `parks_near`, `get_park_details`, `check_alerts`) to
gather graph-grounded facts.
3. **Remember what you learn.** When the user clearly states a like or dislike (e.g. "I love
dark skies," "easy hikes only"), call `save_preference` to remember it, and tell the user
what you saved.
Finally, you talk to the agent through what Eve calls a channel. In a Next.js app you can run both together with withEve, which proxies the agent same-origin behind your app so the browser's auth cookie reaches it:
// next.config.ts
import { withEve } from 'eve/next';
export default process.env.DISABLE_EVE === '1' ? nextConfig : withEve(nextConfig);
Here's what that architecture looks like all together:

That's the runtime, and it's great. But notice what's not in there: anywhere for a fact like "this user loves dark skies and avoids crowds" to live across sessions, or for the agent to remember why it recommended a particular park last week. That's memory, and it's a separate concern that Eve deliberately leaves up to you.
Memory Isn't A Pile Of Embeddings - It's A Context Graph#
The reflex solution here is to throw the conversation into a vector store and retrieve similar chunks later. That gets you fuzzy recall of text, but it doesn't give you a queryable model of the user - and it definitely can't connect that user to your application's own data. To be clear, this isn't an argument for graph instead of vectors - NAMS uses vector search too, for semantic recall.
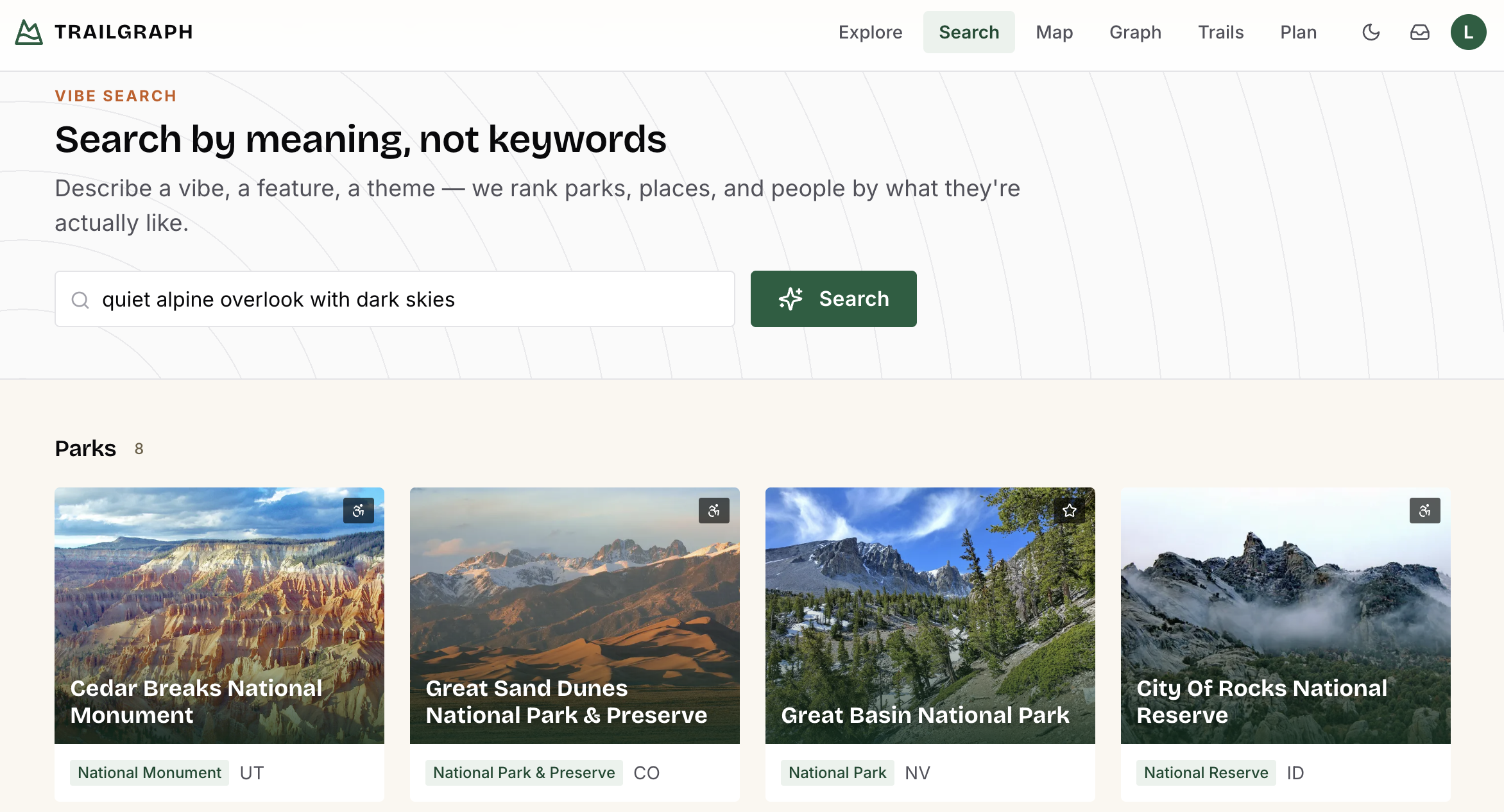
It's that vectors alone aren't enough: vector stores give you recall; the graph gives you understanding. TrailGraph's /search page is exactly this hybrid - vector similarity (db.index.vector.queryNodes) finds the candidate parks, places, and people, and the graph supplies the structure: which park a place belongs to, which person ties to which site.
NAMS takes a more complete position: agent memory is a knowledge graph made up of three distinct memory types.

- Short-term memory is the conversation itself: messages, session history, running summaries, and derived reflections and observations.
- Long-term memory is the entities and the relationships between them, extracted automatically from the conversation using the POLE+O model (Person, Organization, Location, Event, plus Object) as a base with a domain-specific tuned ontology to drive knowledge graph construction. This is also where typed preferences live, along with their confidence and feedback.
- Reasoning memory is the agent's own decision traces and tool-call provenance - the steps and tool calls that produced an answer. Most memory systems stop at "what the user said" and never record "why the agent did what it did." It's what lets the agent honestly answer "why did you recommend that?" from a stored trail rather than improvising a plausible-sounding reason after the fact. We'll see it earn its keep later, in the
explain_recommendationtool.
Here's the detail that makes all of this pay off: NAMS is a memory service built on Neo4j. You can point it at an external Neo4j database that you own - the same database that holds your application's domain data - and your agent's memory becomes graph data you can query directly. And the reason a graph database matters (rather than just "a graph") is that Cypher, vector search, full-text, and point indexes all live in one place, so memory, your domain, and similarity search are all queryable together.
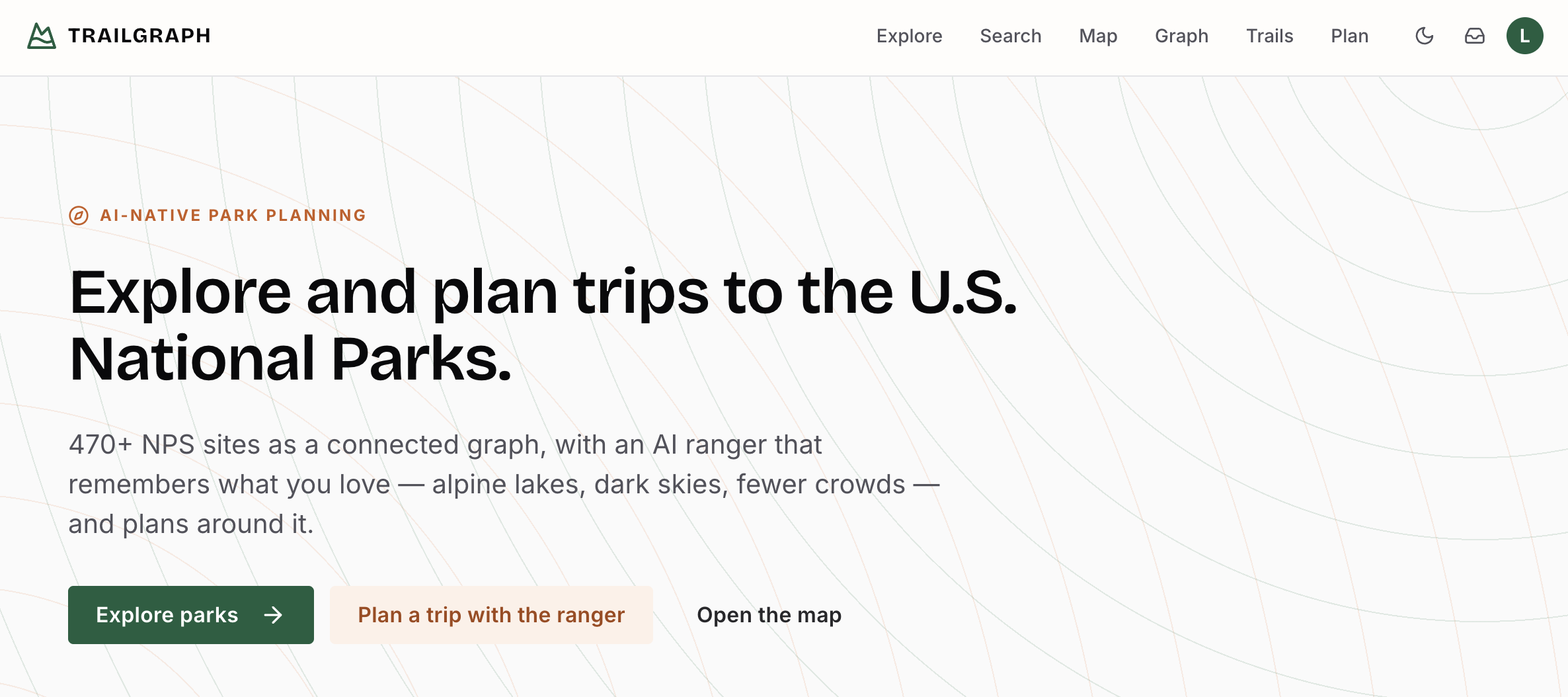
Meet TrailGraph#
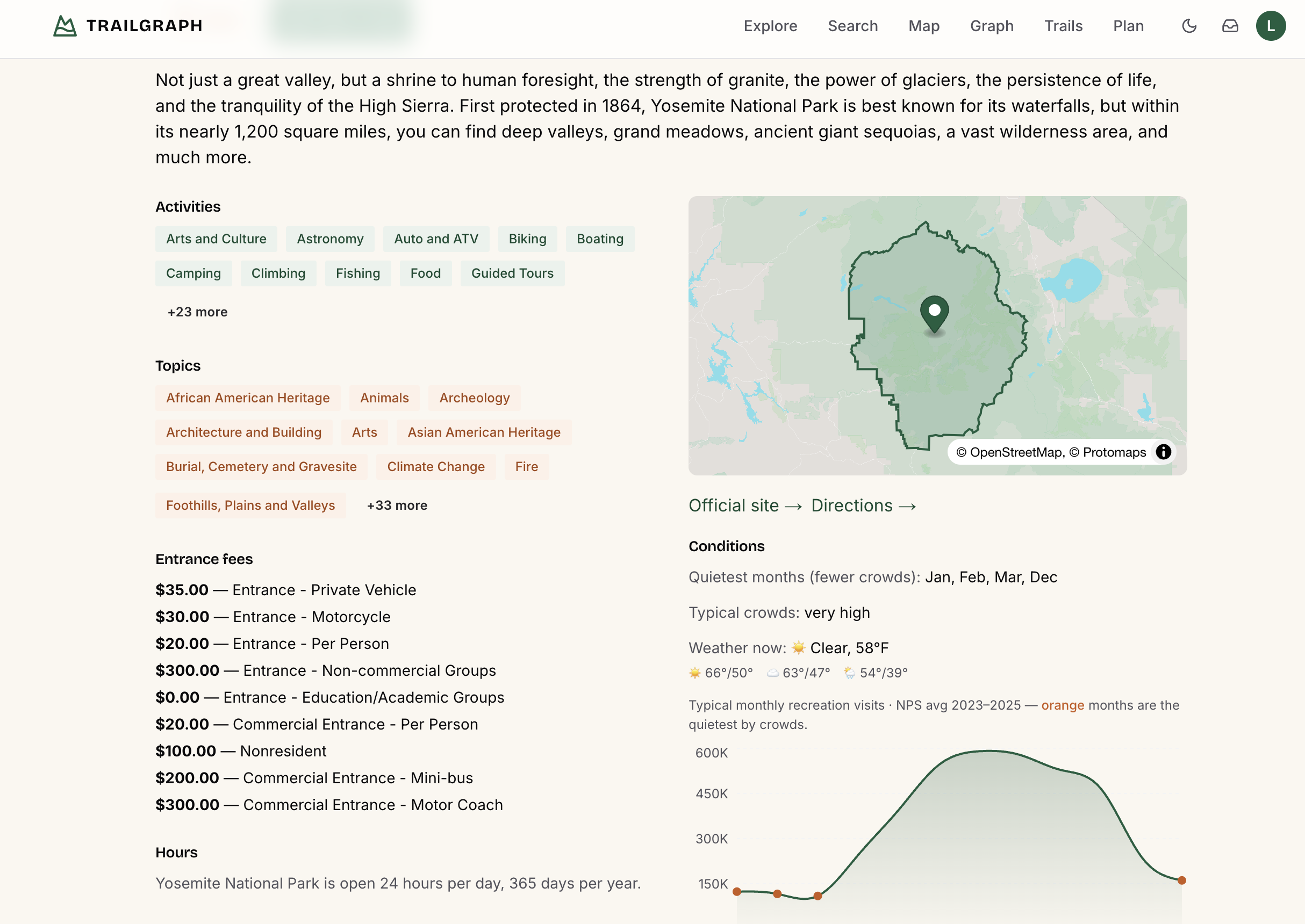
TrailGraph turns the National Park Service's open data into a connected graph - parks, activities, topics, campgrounds, alerts, plus people, places, amenities, passport stamps, passes, and live conditions (weather, crowds, dark-sky) - and layers a conversational "ranger" on top. The interesting part was never the chatbot though; it's that the ranger has graph-native memory, so personalization shows up everywhere in the app, not just in the chat box. (Every new NPS entity type became a new node and a new bridge target for memory - and the denser the domain graph, the stronger the "one hop away" payoff we'll get to.)
The ranger ("Ranger") runs on a single Claude model and a directory of 22 tools, each one its own file. Most are ordinary domain code - graph queries dressed up as tools: a dozen-odd discovery and trip-planning tools (find_parks, parks_near, find_trail, get_park_details, build_itinerary, start_trip_from_tour, and friends; the full list is in the repo). The handful this post is actually about are the memory tools, which read and write the per-user context graph:
recall_user_context- load the user's saved preferences, observations, and prior trips at the start of a turn.save_preference- persist an explicit preference the user stated, writing both to NAMS and a canonical bridge edge.set_travel_constraints- remember accessibility / RV-length / required-amenity constraints to honor in every plan.set_availability- remember the user's travel dates.record_pass- remember an entrance pass the user holds (so trip costs reflect it).recommend_for_user- personalized, novelty-aware park recommendations from saved preferences, recording each as "considered."explain_recommendation- explain why a park fits the user, grounded in the graph path from their preferences to the park.
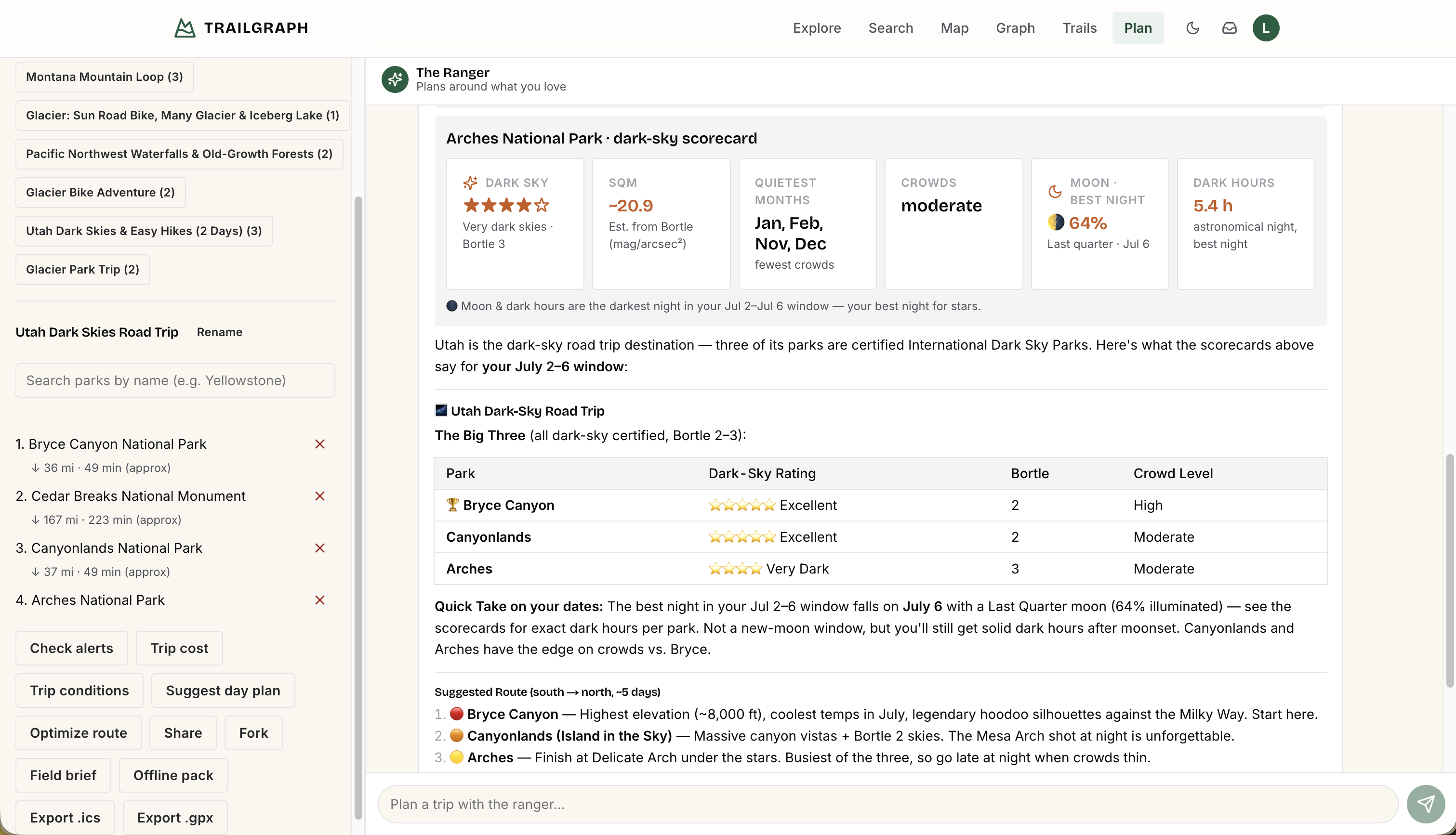
To make the payoff concrete, here's what that same returning user hears once the memory layer is in place - the mockup above shows the same exchange visually:
Avery: Hey, I'm back - any ideas for my next trip?
Ranger: Welcome back, Avery! Still chasing dark skies and alpine lakes? If so, Glacier is a great match - it has world-class stargazing and a string of alpine lakes, both things you've told me you love.
Everything below is the memory layer that produces that reply. Before we dive into the code, here's how the three pieces fit together - the whole integration comes down to three seams:
- Hooks → persistence. Eve hooks fire after every turn and write messages and reasoning to NAMS, so memory is captured deterministically rather than whenever the model remembers to.
- Channel auth → identity. The Eve channel resolves the signed-in user once, and that identity becomes the NAMS
namespace, so every read and write is scoped to the right person. - Tools → NAMS + Cypher. Tools recall and save through NAMS, and read across the domain and context graphs with a single Cypher query.
The next four sections build those seams up one at a time - wrap, persist, identify, recall - and then we get to the payoff.
Neo4j Agent Memory For TypeScript#
A quick note on names before we dive in, because three closely-related things share the "agent memory" naming - it's really package vs. service vs. SDK:
neo4j-agent-memory- the Python package: the original system that runs ontology driven extraction, the three memory types, agent framework specific integrations and the graph schema against Neo4j.- NAMS (the Neo4j Agent Memory Service) - that same system delivered as a hosted service: you don't run the Python library yourself, you call an API or use the TypeScript/Python SDKs to integrate with your agent framework.
@neo4j-labs/agent-memory- the TypeScript SDK for NAMS. Because NAMS is just an HTTP API, a TypeScript app like TrailGraph gets the full memory system without ever touching Python. It's the SDK every snippet below uses.
Every memory call in the app goes through a single MemoryGateway interface, and the only file that imports the Neo4j Agent Memory SDK directly is the adapter sitting behind it. That way, if the NAMS API surface changes, only one file has to change.

That SDK is nicely typed - the MemoryClient exposes shortTerm, longTerm, reasoning, and a read-only query.cypher. Memory reads and writes are scoped by a namespace which we set to the user's id to isolate memory access scoped per user:
// lib/memory.ts (the adapter behind MemoryGateway)
import { MemoryClient } from '@neo4j-labs/agent-memory';
private clientFor(userId: string): MemoryClient {
let c = this.clients.get(userId);
if (!c) {
c = new MemoryClient({
apiKey: env.nams.apiKey,
workspaceId: env.nams.workspaceId || undefined,
namespace: userId, // ← the isolation boundary
});
this.clients.set(userId, c);
}
return c;
}
If the workspaceId / namespace distinction is fuzzy: the workspace is the app-level scope (one TrailGraph), and the namespace is the per-user partition within it that isolates one user's memory from another's.
Adding a message or recording reasoning then reads naturally off the typed sub-clients. Note that bulkAddMessages caps out at 100 messages per call, so we batch:
async addMessages(userId, conversationId, messages) {
const client = this.clientFor(userId);
for (let i = 0; i < messages.length; i += 100) {
await client.shortTerm.bulkAddMessages(conversationId, messages.slice(i, i + 100));
}
}
The nice thing about this boundary is that isolation is now enforced in one place - a single accidentally-shared client can't leak entities across users.
Deterministically Persisting Every Turn With A Hook#
The naive approach to saving memories is to give the model a save_message tool and just hope it remembers to call it. I'd recommend against that. Model discipline isn't a persistence strategy - you'll silently lose memory the first time the model decides a turn isn't worth a tool call.
Eve has a much better primitive for this: hooks. A hook subscribes to harness events that fire deterministically after the model finishes, which turns persistence into a runtime guarantee rather than a hope.

Here's the heart of the hook - it just maps the three harness events to a persist call:
// agent/hooks/persist-turn.ts
export default defineHook({
events: {
'message.received': (event, ctx) => persist(ctx, 'user', event.data.message),
'message.completed': (event, ctx) => persist(ctx, 'assistant', event.data.message ?? ''),
'reasoning.completed': (event, ctx) => persistReasoning(ctx, event.data.reasoning),
},
});
The two helpers (persist and persistReasoning) resolve the server-bound userId from ctx.session.auth.current.principalId, look up the NAMS conversation, and write - each wrapped in a try/catch that logs non-fatally, because a slow Labs service should never break a user's turn. And because userId comes from the session rather than anything the model controls, persistence is also un-spoofable, which brings us to the topic of identity.
Binding Identity To The Session#
If userId were a tool input, the model could put anything there, and that's a memory-poisoning vector waiting to happen. So in TrailGraph no tool accepts a userId at all. Identity flows from the Better Auth cookie, through the Eve channel's auth function, into the session - and tools read it from there.

Here's the channel AuthFn that resolves the signed-in user; we register it on the channel with eveChannel({ auth: [betterAuthAuth(), localDev(), vercelOidc()] }), and the first matching function wins:
// lib/eve-auth.ts — a channel AuthFn that resolves the signed-in user
export function betterAuthAuth(): AuthFn<Request> {
return async (request) => {
const session = await auth.api.getSession({ headers: request.headers }).catch(() => null);
if (!session?.user) return null; // fall through to localDev / oidc
return { principalId: session.user.id, principalType: 'user', authenticator: 'better-auth' };
};
}
Every tool then derives identity the same boring, un-spoofable way:
// lib/agent-ctx.ts
export function callerId(ctx: ToolContext): string {
const id = ctx.session?.auth?.current?.principalId;
if (!id) throw new Error('Unauthenticated agent session');
return id;
}
Keeping userId out of every inputSchema like this means the model simply has nothing to spoof.
Recalling Memory And Saving Preferences#
With persistence and identity handled, the agent actually needs to use its memory. Two tools do most of the work here.
The first, recall_user_context, pulls the user's saved preferences and prior observations at the top of a turn. Its inputSchema is literally empty, because identity is bound to the session on the server:
// agent/tools/recall_user_context.ts
import { defineTool } from 'eve/tools';
import { z } from 'zod';
import { memory } from '../../lib/memory';
import { callerId, sessionId } from '../../lib/agent-ctx';
export default defineTool({
description: "Recall the current user's saved preferences, interests, observations, and prior trips.",
inputSchema: z.object({}),
async execute(_input, ctx) {
const userId = callerId(ctx);
const conversationId = sessionId(ctx);
// short-term context (reflections, observations) + long-term preferences, shaped for the model
const [context, prefs] = await Promise.all([
memory.getConversationContext(userId, conversationId),
memory.searchEntities({ userId, type: 'preference' }),
]);
return { kind: 'map_snippet', data: { ...context, preferences: prefs } };
},
});
The second, save_preference, is a memory-write tool for intentional "remember that I..." facts. The instructions tell the ranger to call it whenever a user clearly states a like or a dislike, and then to say out loud what it saved:
// agent/tools/save_preference.ts
import { defineTool } from 'eve/tools';
import { z } from 'zod';
import { recordPreference } from '../../lib/bridges';
import { callerId } from '../../lib/agent-ctx';
// Intentional "remember that I prefer X" facts.
// Writes the raw fact to NAMS AND a deterministic canonical bridge edge.
// userId is server-bound, never model input.
export default defineTool({
description:
"Persist an explicit user preference the user clearly stated (e.g. 'I prefer campgrounds', 'I love dark skies', 'I avoid crowds').",
inputSchema: z.object({
category: z.enum(['activity', 'topic', 'terrain', 'vibe', 'crowd', 'season', 'accessibility', 'budget']),
value: z.string(),
}),
async execute({ category, value }, ctx) {
const userId = callerId(ctx);
const result = await recordPreference({ userId, category, value });
return { kind: 'map_snippet', data: { saved: { category, value }, ...result } };
},
});
This is the moment where the context graph really earns its name, so it's worth looking closely at what save_preference does under the hood. It writes the raw fact to NAMS and a deterministic edge into the graph. Let's see why that second write matters so much.
One Graph For Domain And Memory#
Here's the architectural decision that everything has been building toward: TrailGraph's domain graph and its per-user context graph live in the same Neo4j database. NAMS writes memory directly into the database that already holds all the parks.
Why does that matter? There's no cross-system join and no syncing a vector database against a SQL database - the user's memory and the world's data are in the same graph.
The user's preferences end up sitting one hop away from the domain entities that satisfy them. "Find the parks that match what this person loves" becomes a single graph traversal, not a cross-system join.

The diagram simplifies the domain side to three node types to keep it readable; in reality it's the full NPS graph - people, places, amenities, campgrounds, passport stamps, and more - and every one of those is a potential bridge target for memory.
The bridge between the two graphs is built by canonicalizing the user's words to a real domain node. "I love dark skies" doesn't get stored as a free-floating string - it resolves to the :Activity {name: "Astronomy"} node that the entire domain graph already understands, and then we draw the edge:

Now the recommendation that makes a graph beat a vector store is just a bit of Cypher. Here's the naïve version - start at the user, walk their preferences, arrive at the matching parks (we'll make it real, with novelty and travel constraints, in a moment):
MATCH (u:User {userId: $me})-[:PREFERS]->(a)<-[:OFFERS]-(p:Park)
RETURN p
In other words, "give me the parks that offer the activities this user prefers" - the user's memory and the world's data, traversed together in a single query.
Memory That Honors Constraints, Not Just Preferences#
So far memory has been about what the user likes. But the strongest version of "an agent that knows you" remembers the constraints you travel under and honors them in every plan - and that is exactly the kind of structured, queryable reasoning a graph does and a vector store can't.
So preferences aren't the only thing written into the context graph. A second family of memory-write tools captures hard travel constraints, each as its own bridge from the user into the domain graph:
set_travel_constraints→(:User)-[:TRAVELS_WITH]->(:Constraint {wheelchair, rvMaxLengthFt})and(:User)-[:REQUIRES]->(:Amenity)set_availability→(:User)-[:AVAILABLE]->(:Season {start, end})record_pass→(:User)-[:HOLDS]->(:EntrancePass), and collecting a stamp writes(:User)-[:COLLECTED]->(:PassportStamp)
The capture tool looks just like save_preference, only it writes constraint edges instead of a preference:
// agent/tools/set_travel_constraints.ts
export default defineTool({
description:
"Remember the user's accessibility / travel constraints (wheelchair, RV length in feet, required amenities) so all recommendations respect them.",
inputSchema: z.object({
wheelchair: z.boolean().optional(),
rvMaxLengthFt: z.number().optional(),
requiredAmenities: z.array(z.string()).optional().describe('Exact NPS amenity names the user requires'),
}),
async execute(input, ctx) {
// server-bound userId, then setTravelConstraints() writes the
// TRAVELS_WITH / REQUIRES bridges (full version in the repo)
},
});
Now the recommendation query does real work that a similarity search simply can't: it walks the user's preferences to candidate parks and filters by their hard constraints, in one traversal. Tell the ranger "I travel in a 28-ft RV" and every pick afterward only includes parks with a campsite that fits:
// lib/recommend.ts — forYou(): preferences + constraints in one traversal (trimmed)
MATCH (u:User {userId: $userId})-[pr:PREFERS]->(d)
MATCH (p:Park)-[:OFFERS|HAS_TOPIC]->(d)
WHERE NOT (u)-[:CONSIDERED]->(p) // novelty: skip what they've seen
AND ($rv IS NULL OR EXISTS { // RV must fit a campsite
(p)<-[:IN_PARK]-(cg:Campground) WHERE cg.rvMaxLengthFt >= $rv })
AND (NOT $wheelchair OR EXISTS { // wheelchair-accessible campground
(p)<-[:IN_PARK]-(cg:Campground) WHERE cg.wheelchairAccessible = true })
AND ALL(req IN $required WHERE // every required amenity present
EXISTS { (p)-[:HAS_PLACE]->(:Place)-[:HAS_AMENITY]->(:Amenity {name: req}) })
WITH p, sum(coalesce(pr.weight, 1.0)) AS score
RETURN p.parkCode AS parkCode, p.fullName AS name ORDER BY score DESC LIMIT toInteger($limit)
The user's likes and the constraints they travel under live one hop from the parks that satisfy them, so "find parks I'd love that also fit my rig" is a single query - not a recommendation engine, a vector lookup, and a post-filter stitched together.
And this query isn't only for the chat: it backs a live "Refine" panel on the recommendations view. Drag a constraint - dark-sky ≤ Bortle N, fits my RV, fewer crowds - and the same Cypher re-traverses and re-ranks in place (a single Bortle filter narrows 474 parks to 10 instantly). That's the structured filter a vector index can't do cleanly.
Reasoning Memory And Honest Explanations#
This is the memory type most systems skip - and it's worth being precise about what it is, because two different things happen when the agent answers "why this park?", and they live in two different places.
First, the provenance the user sees is read straight from the graph. The explain_recommendation tool hands a parkCode to explainRecommendation, which walks the grounding edges - the user's PREFERS edges that the park OFFERS or HAS_TOPIC - and returns the matched nodes alongside the user's own words:
// lib/explain.ts — the "why", read from grounding edges (not model-generated)
MATCH (p:Park {parkCode: $parkCode})
OPTIONAL MATCH (u:User {userId: $userId})-[r:PREFERS]->(d)
WHERE (p)-[:OFFERS]->(d) OR (p)-[:HAS_TOPIC]->(d)
RETURN p.fullName AS park,
collect(DISTINCT { name: d.name, yourWords: r.value }) AS matches
Because the explanation is assembled from edges rather than asked of the model, it can't hallucinate: every clause maps to a relationship that either exists or doesn't. A second query adds the constraint clauses (a wheelchair-accessible or RV-fitting campground), so the ranger can say: "I suggested Glacier because you love dark skies (→ Astronomy) and alpine lakes (→ Lakes), and it has a campground site that fits your 28-ft RV." Each clause is backed by a PREFERS / OFFERS / HAS_TOPIC edge, or a Campground with rvMaxLengthFt.
Second - and this is the actual reasoning memory - the agent's own decision trace is recorded every turn by the persist hook. That one doesn't live in your Neo4j; it's written to NAMS reasoning memory through the SDK, as a step with its child tool calls:
// lib/memory.ts — recordReasoning() writes the turn's trace to NAMS reasoning memory
async recordReasoning(userId, step) {
const client = this.clientFor(userId);
const agentStep = await client.reasoning.recordStep({
conversationId: step.conversationId,
reasoning: step.summary, // the agent's stated rationale
actionTaken: step.actionTaken ?? (step.toolCalls ?? []).map((t) => t.tool).join(', ') || 'respond',
result: step.result,
});
for (const tc of step.toolCalls ?? []) { // one child per tool the turn invoked
await client.reasoning.recordToolCall(agentStep.id, tc.tool, tc.input ?? {}, { result: tc.output });
}
}
So the two are complementary: the grounding is graph-native and queryable - it's what powers the user-facing "why" - while the reasoning trace (steps and tool calls) lives in NAMS so a turn is auditable after the fact. Most systems record neither; recording both is the cheapest bit of trust you'll ever buy.
And these traces aren't only stored - the ranger now surfaces them inline as a turn runs: a "Used N tools" strip (✓ Recalling your context · ✓ Tonight's sky · Checking weather) and an expandable "Ranger's reasoning" disclosure show the very steps the persist hook writes to NAMS, live.

This isn't hypothetical: every recommendation card in TrailGraph carries a "Why this park?" popover that renders exactly these edges - You → PREFERS → Lakes → HAS_TOPIC → Glacier, captioned with the words you actually used ("you said 'alpine lakes'").
Memory That Escapes The Chat Box#
Here's the quiet superpower of storing memory as graph data: non-chat surfaces can read it too. The context graph isn't trapped behind the conversation API - it's just nodes and edges in Neo4j, so the homepage, the map, and the recommendation engine can all query the same preferences.

And users can see and steer it. TrailGraph's "Your memory" page lays the whole context graph out for editing: remembered preferences (with the original words, and Less/More controls to reweight them), the "How you travel" constraints (wheelchair, RV length, travel dates), passes and collected stamps, the parks they've considered, and their trips - each row with feedback and a delete button.
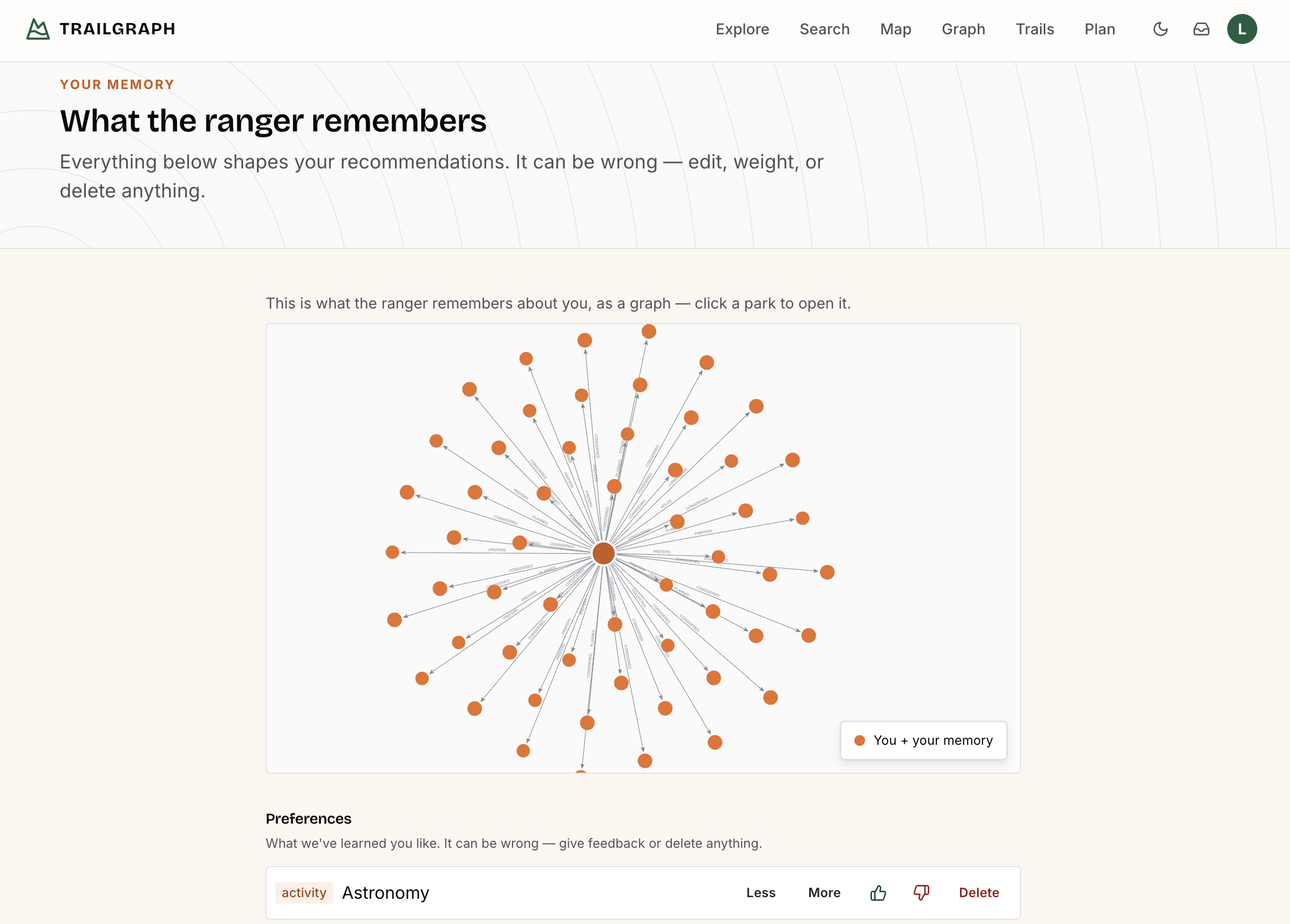
The clearest "this is a graph" surface is /trails. People and topics in the domain graph aren't decoration - they connect parks to each other. A trail is the set of parks tied together by one historical figure or one theme, which is just a traversal: ask for Ansel Adams and you get the parks he photographed; ask for "Civil Rights" and you get the parks that carry that topic. The ranger reaches the same data through its find_trail and find_person tools to seed a multi-park trip.
// the parks connected by a person - one hop (the topic variant swaps in HAS_TOPIC)
MATCH (per:Person {name: $name})-[:ASSOCIATED_WITH]->(p:Park) RETURN p
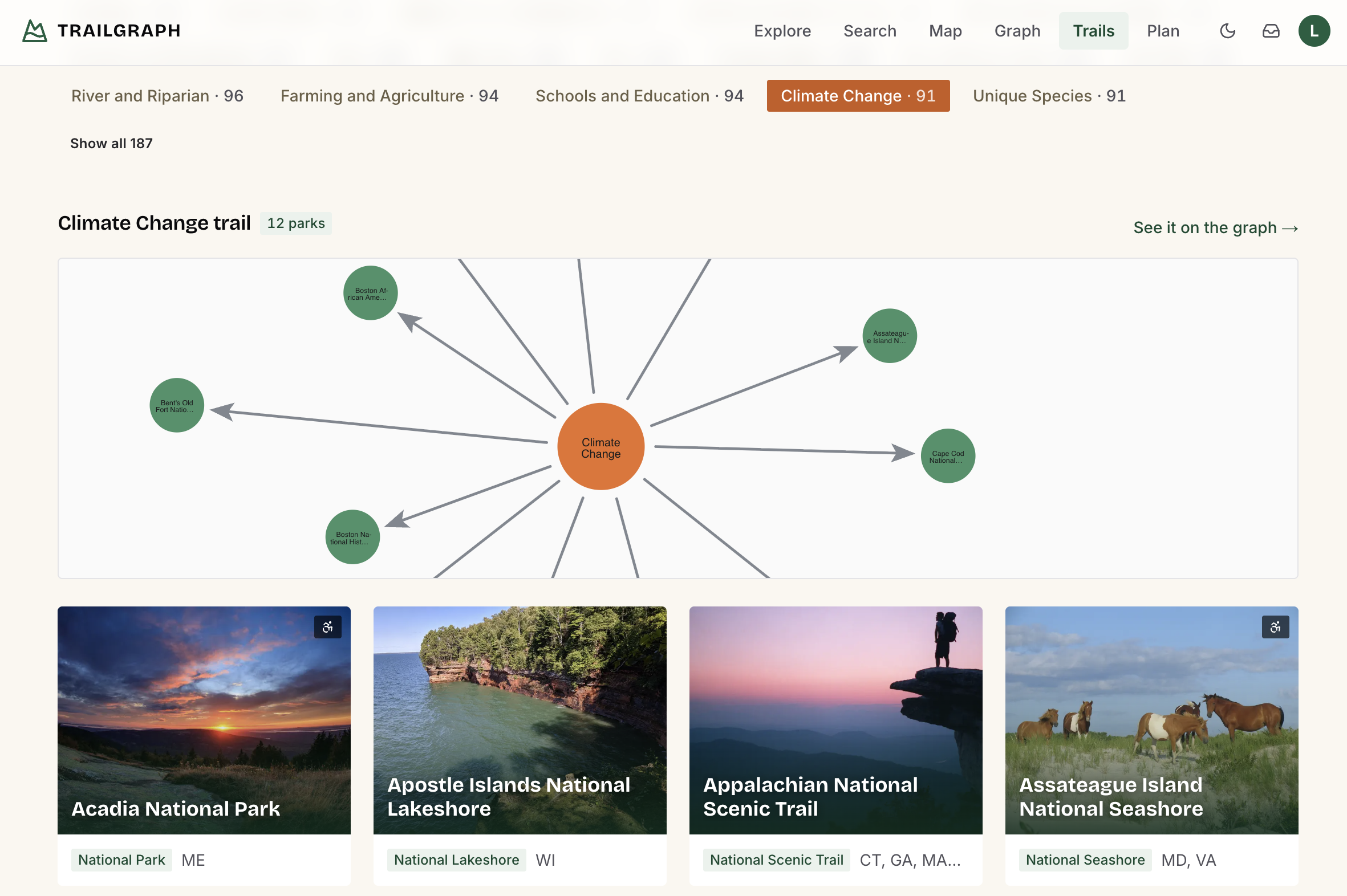
It's a nice payoff for treating people as first-class nodes - the same instinct behind the Person in POLE+O - rather than as strings buried in a park description.
What's Next?#
If you're building on Eve, the memory layer is the part that's really worth getting right, and the nice thing is that you don't have to build it from scratch. To recap, here's the recipe we walked through:
- Wrap the SDK behind a
MemoryGateway, with oneMemoryClientper user (namespace = userId). - Persist in a hook, not a tool - subscribe to
message.received,message.completed, andreasoning.completed. - Bind identity in the channel's
AuthFn, and keepuserIdout of every tool input. - Point NAMS at your own Neo4j and write bridge edges from each
Userto your real domain nodes. That single decision is what turns "a chatbot with recall" into an app that actually knows its users.
The stack is Eve as the agent runtime, NAMS is the memory layer, and Neo4j is the substrate that makes that memory queryable and co-resident with your world. Put the three together and you get something a chatbot-over-an-API simply can't be: an agent whose memory is a queryable graph of the user and the world, available to every corner of your product.
There are a couple of threads I want to dig into in future posts. The first is the collective-intelligence angle - opt-in "travelers like you also loved..." recommendations as a single cross-user traversal over the shared memory graph. The second is how to actually evaluate memory quality: measuring whether the agent is remembering the right things and recalling them at the right moment, which turns out to be harder (and more interesting) than it sounds. If either of those sounds useful, the newsletter below is the best way to catch them.
Resources#
- Give TrailGraph a try
- TrailGraph code on GitHub
- Neo4j Agent Memory Service (NAMS)
@neo4j-labs/agent-memoryon npm- Vercel Eve
- Better Auth
TrailGraph is a demo, not an official NPS source - always defer to NPS.gov and rangers for life-safety decisions.
Stay Updated
Get notified about new posts and videos