Scraping Russian Twitter Trolls With Python, Neo4j, and GraphQL
William Lyon
November 12, 2017
10 min read
Last week as a result of the House Intelligence Select Committee investigation, Twitter released the screen names of 2752 Twitter accounts tied to Russia's Internet Research Agency that were involved in spreading fake news, presumably with the goal of influencing the 2016 election. In this post we explore how to scrape tweets from the user pages of cached versions of these pages, import into Neo4j for analysis, and how to build a simple GraphQL API exposing this data through GraphQL.
Russian Twitter Trolls
While Twitter released the screen names and user ids of these accounts, they did not release any data (such as tweets or follower network information) associated with the accounts. In fact, Twitter has suspended these accounts which means their tweets have been removed from Twitter.com and are no longer accessible through the Twitter API. Analyzing the tweets made by these accounts is the first step in understanding how social media accounts run by Russia may have been used to influence the US Election. So our first step is simply to find potential sources for the data.
Internet Archive
Internet Archive is a non-profit library that provides cached version of some websites: a snapshot of a webpage at a given point in time that can be viewed later. One option for obtaining some of the Russian Troll tweets is by using Internet Archive to find any Twitter user pages that may have been cached by Internet Archive.
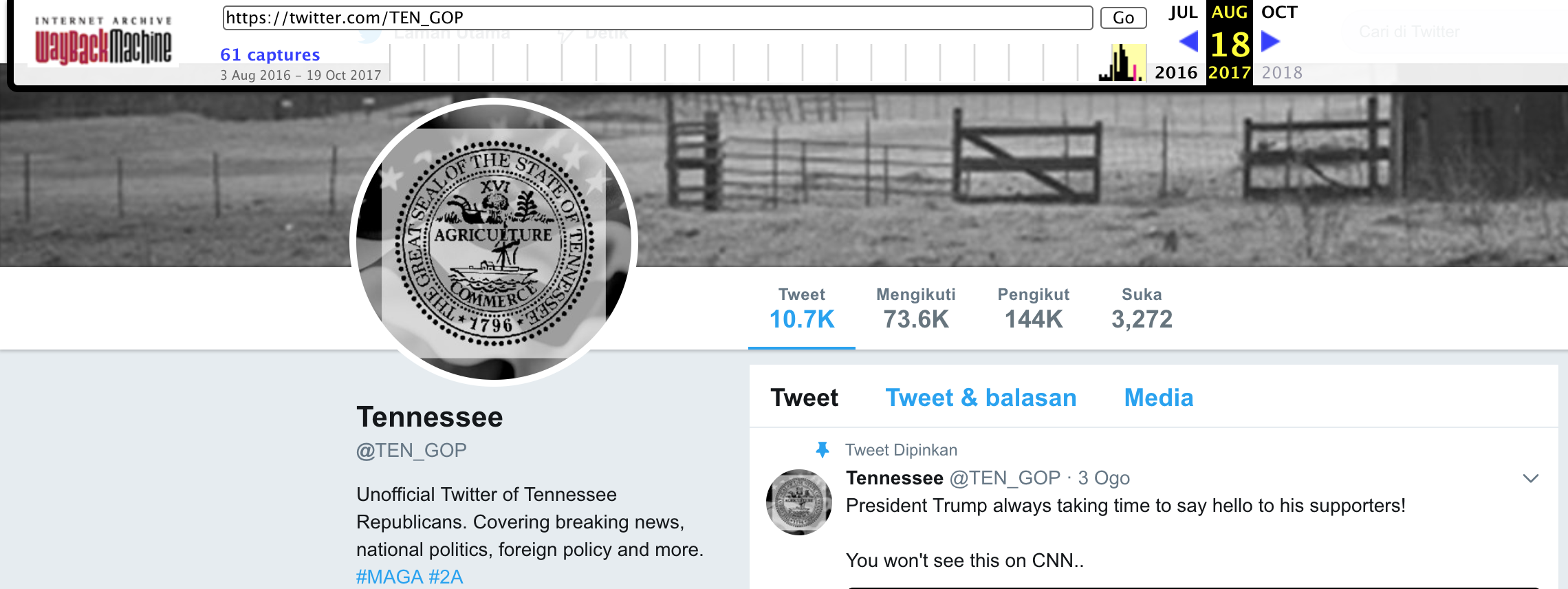
For example, if you visit http://web.archive.org/web/20170818065026/https:/twitter.com/TEN_GOP we can see the Twitter page for @TEN_GOP, one of the Russia Troll accounts that was designed to look like an account associated with the Tennessee Republican party.
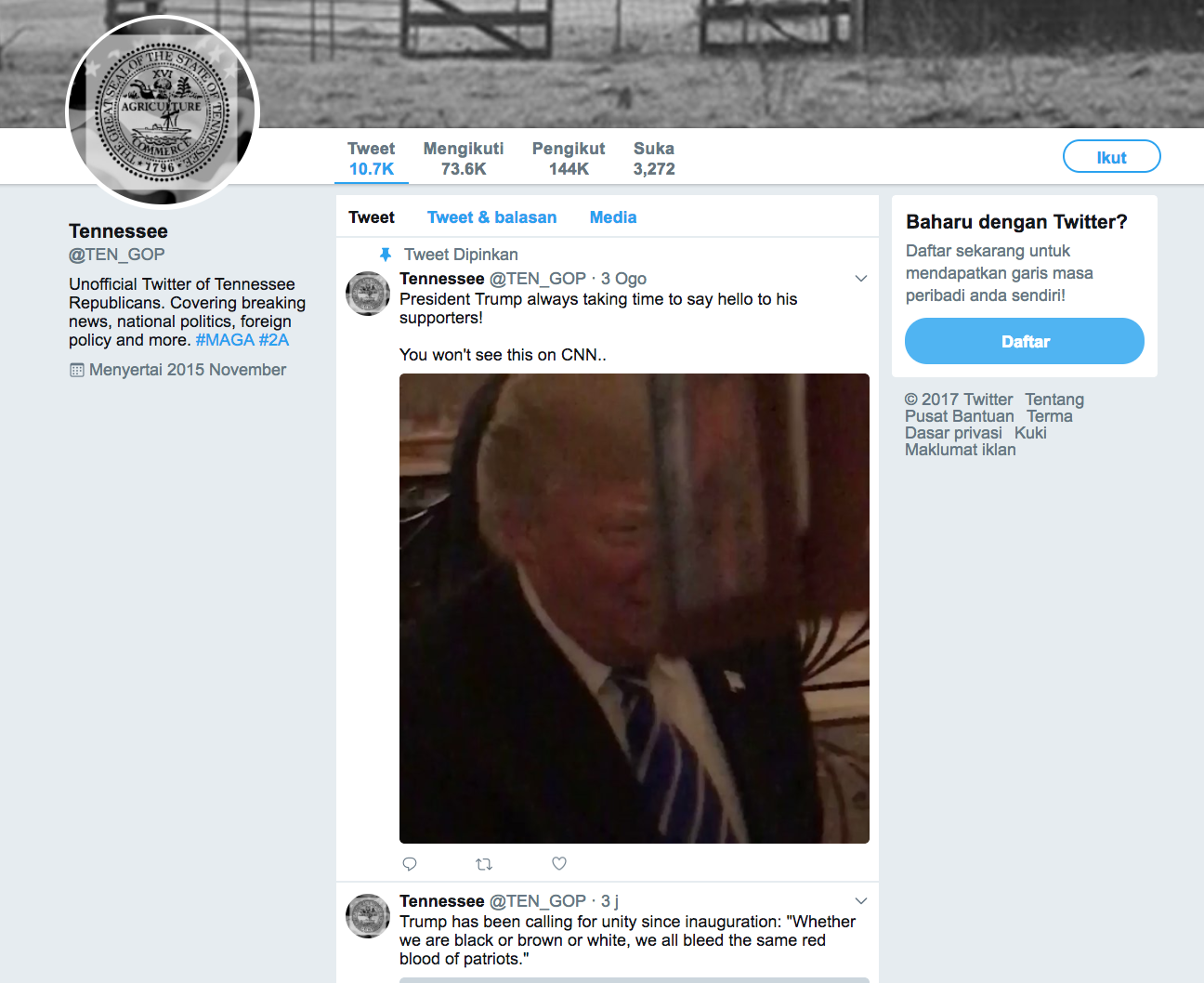
This snapshot page contains several of @TEN_GOP's most recent tweets (before the snapshot was taken by Internet Archive).
Finding Available Cached Pages#
Using the screen names provided by the House Intelligence Committee we can use Internet Archive's Wayback API to see if the user's Twitter profile page was cached by Internet Archive at any point in time. We'll write a simple Python script to iterate through the list of Russian Troll twitter accounts, checking the Wayback API for any available cached pages.
We can do this by making a request to http://archive.org/wayback/available?url=http://twitter.com/TWITTER_SCREEN_NAME_HERE. This will return the url and timestamp of any caches made, if they exist.
So we iterate through the list of twitter screen names, checking the Wayback API for any available caches.
import requests
items = []
initial = "http://archive.org/wayback/available"
# iterate through list of flagged twitter screen names
with open('./data/twitter_handle_urls.csv') as f:
for line in f:
params = {'url': line}
r = requests.get(initial, params=params)
d = r.json()
#print(d)
items.append(d)
# write URL of any available archives to file
with open('./data/avail_urls.txt', 'w') as f:
for item in items:
if 'archived_snapshots' in item:
if 'closest' in item['archived_snapshots']:
f.write(item['archived_snapshots']['closest']['url'] + '\n')
With this, we end up with a file twitter_handle_urls.csv that contains a list of Internet Archive urls for any of the Russian troll accounts that were archived by Internet Archive. Unfortunately, we only find just over 100 Russia Troll accounts that were cached by Internet Archive. This is just a tiny sample of the overall accounts, but we should still be able to scrape tweets for these 100 users.
Scraping Twitter Profile Pages#
Now, we're ready to scrape the HTML from the Internet Archive caches to extract all the tweet content that we can.
We'll make use of the BeautifulSoup Python package to help us extract the tweet data from the HTML. First, we'll use Chrome devtools to inspect the structure of the HTML, seeing what elements contain the data we're looking for:
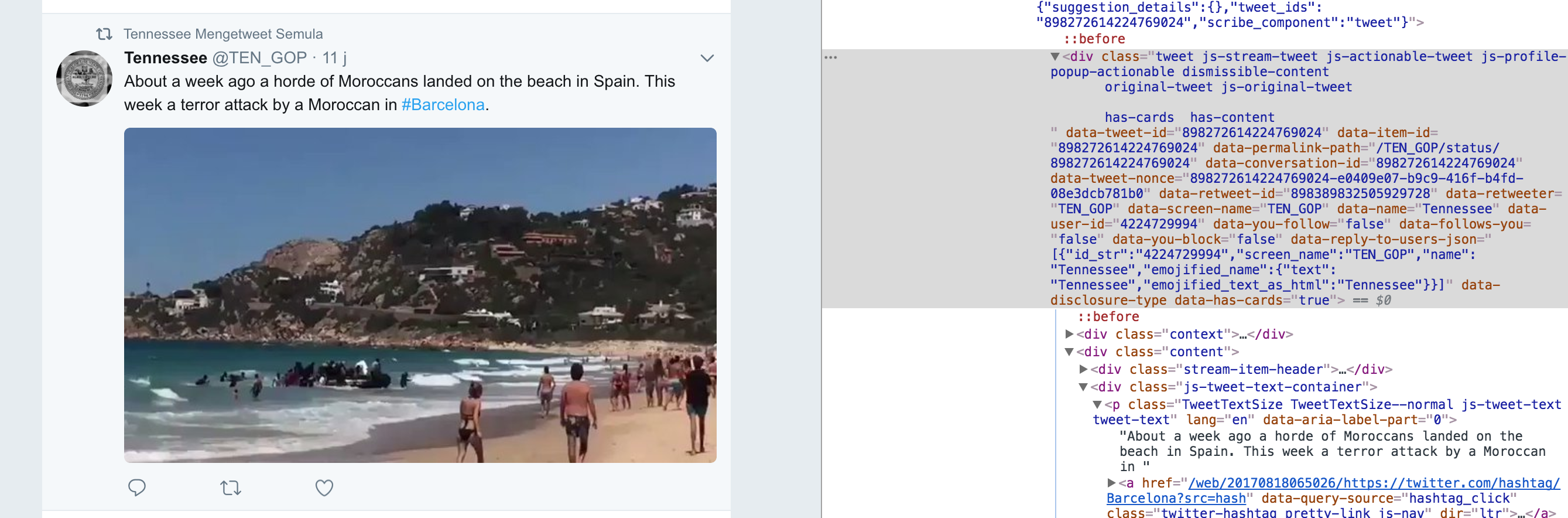
Since the caches were taken at different times, the structure of the HTML may have changed. We'll need to write code that can handle parsing these different formats. We've found two versions of the Twitter user pages in the caches. One from ~2015, and one used around ~2016-2017.
Here is the code for scraping the data for one of the versions. The full code is available here.
import urllib
from bs4 import BeautifulSoup
import csv
import requests
# testing for new version
url = "http://web.archive.org/web/20150603004258/https://twitter.com/AlwaysHungryBae"
page = requests.get(url).text
soup = BeautifulSoup(page, 'html.parser')
tweets = soup.find_all('li', attrs={'data-item-type': 'tweet'})
for t in tweets:
tweet_obj = {}
tweet_obj['tweet_id'] = t.get("data-item-id")
tweet_container = t.find('div', attrs={'class': 'tweet'})
tweet_obj['screen_name'] = tweet_container.get('data-screen-name')
tweet_obj['permalink'] = tweet_container.get('data-permalink-path')
tweet_content = tweet_container.find('p', attrs={'class': 'tweet-text'})
tweet_obj['tweet_text'] = tweet_content.text
tweet_obj['user_id'] = tweet_container.get('data-user-id')
tweet_time = tweet_container.find('span', attrs={'class': '_timestamp'})
tweet_obj['timestamp'] = tweet_time.get('data-time-ms')
hashtags = tweet_container.find_all('a', attrs={'class': 'twitter-hashtag'})
tweet_obj['hashtags'] = []
tweet_obj['links'] = []
for ht in hashtags:
ht_obj = {}
ht_obj['tag'] = ht.find('b').text
ht_obj['archived_url'] = ht.get('href')
tweet_obj['hashtags'].append(ht_obj)
links = tweet_container.find_all('a', attrs={'class': 'twitter-timeline-link'})
for li in links:
li_obj = {}
if li.get('data-expanded-url'):
li_obj['url'] = li.get('data-expanded-url')
elif li.get('data-resolved-url-large'):
li_obj['url'] = li.get('data-resolved-url-large')
else:
li_obj['url'] = li.text
li_obj['archived_url'] = li.get('href')
tweet_obj['links'].append(li_obj)
print(tweet_obj)
BeautifulSoup allows us to select HTML elements by specifying attributes to match against. By inspecting the structure of the HTML page we can see which bits of the tweets are stored in different HTML elements so we know which to grab with BeautifulSoup. We build up an array of tweet objects as we parse all the tweets on the page.
{
'tweet_id': '561931644785811457',
'screen_name': 'AlwaysHungryBae',
'permalink': '/AlwaysHungryBae/status/561931644785811457',
'tweet_text': 'Happy Super Bowl Sunday \n#superbowlfood pic.twitter.com/s6rwMtdLom',
'user_id': '2882130846',
'timestamp': '1422809918000',
'hashtags': [
{'tag': 'superbowlfood',
'archived_url': '/web/20150603004258/https://twitter.com/hashtag/superbowlfood?src=hash'
}
],
'links': [
{'url': 'pic.twitter.com/s6rwMtdLom',
'archived_url': 'http://web.archive.org/web/20150603004258/http://t.co/s6rwMtdLom'
},
{'url': 'https://pbs.twimg.com/media/B8xh2fFCQAE-vxU.jpg:large', '
archived_url': '//web.archive.org/web/20150603004258/https://twitter.com/AlwaysHungryBae/status/561931644785811457/photo/1'
}
]
}
Once we've extracted the tweets we write them to a json file:
# write tweets to file
import json
with open('./data/tweets_full.json', 'w') as f:
json.dump(tweet_arr, f, ensure_ascii=False, sort_keys=True, indent=4)
We end up finding about 1500 tweets from 187 Twitter accounts. This is only a fraction of the tweets sent by the Russian Trolls, but is still too much data for us to analyze by reading every tweet. We'll make use of the Neo4j graph database to help us make sense of the data. Using Neo4j we'll be able to ask questions such as "What hashtags are used together most frequently?", or "What are the domains of URLs shared in tweets that mention Trump?".
Importing Into Neo4j
Now that we have our scraped tweet data we're ready to insert into Neo4j. We have several options for importing data into Neo4j. We'll do our import by loading the JSON data and passing it as a parameter to a Cypher query, using the Python driver for Neo4j.
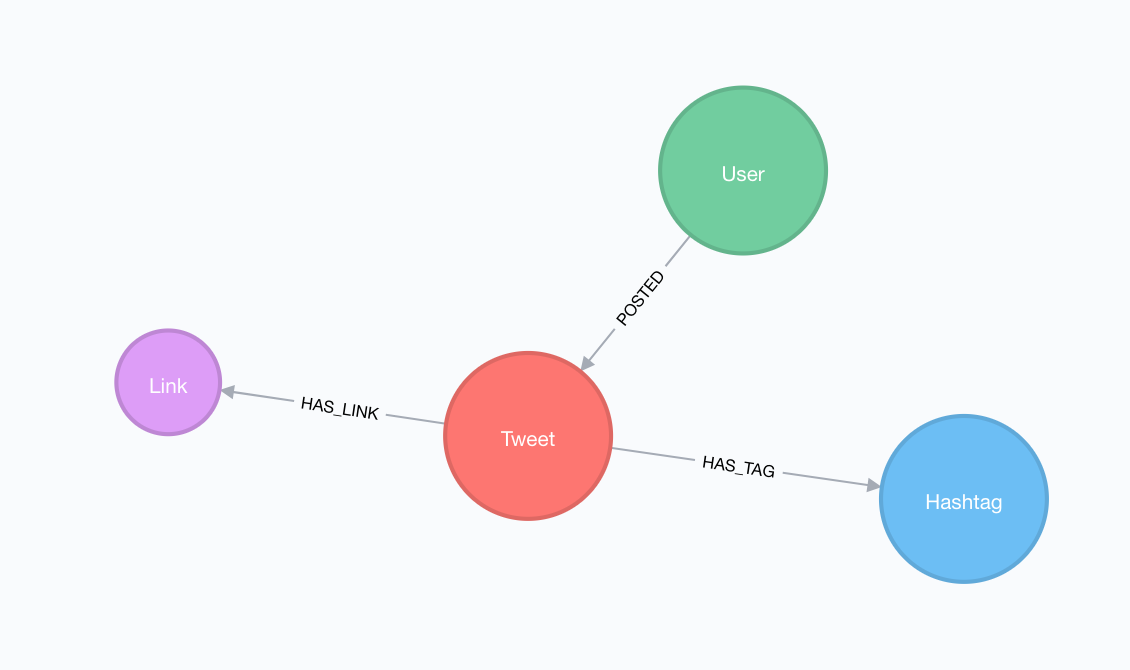
We'll use a simple graph data model, treating Hashtags and Links as nodes in the graph, as well as the Tweet and User who posted the tweet.
Datamodel
from neo4j.v1 import GraphDatabase
import json
driver = GraphDatabase.driver("bolt://localhost:7687")
with open('./data/tweets_full.json') as json_data:
tweetArr = json.load(json_data)
import_query = '''
WITH $tweetArr AS tweets
UNWIND tweets AS tweet
MERGE (u:User {user_id: tweet.user_id})
ON CREATE SET u.screen_name = tweet.screen_name
MERGE (t:Tweet {tweet_id: tweet.tweet_id})
ON CREATE SET t.text = tweet.tweet_text,
t.permalink = tweet.permalink
MERGE (u)-[:POSTED]->(t)
FOREACH (ht IN tweet.hashtags |
MERGE (h:Hashtag {tag: ht.tag })
ON CREATE SET h.archived_url = ht.archived_url
MERGE (t)-[:HAS_TAG]->(h)
)
FOREACH (link IN tweet.links |
MERGE (l:Link {url: link.url})
ON CREATE SET l.archived_url = link.archived_url
MERGE (t)-[:HAS_LINK]->(l)
)
'''
def add_tweets(tx):
tx.run(import_query, tweetArr=tweetArr)
with driver.session() as session:
session.write_transaction(add_tweets)
Graph Queries#
Now that we have the data in Neo4j we can write queries to help make sense of what the Russian Trolls were tweeting about.
Interesting Queries
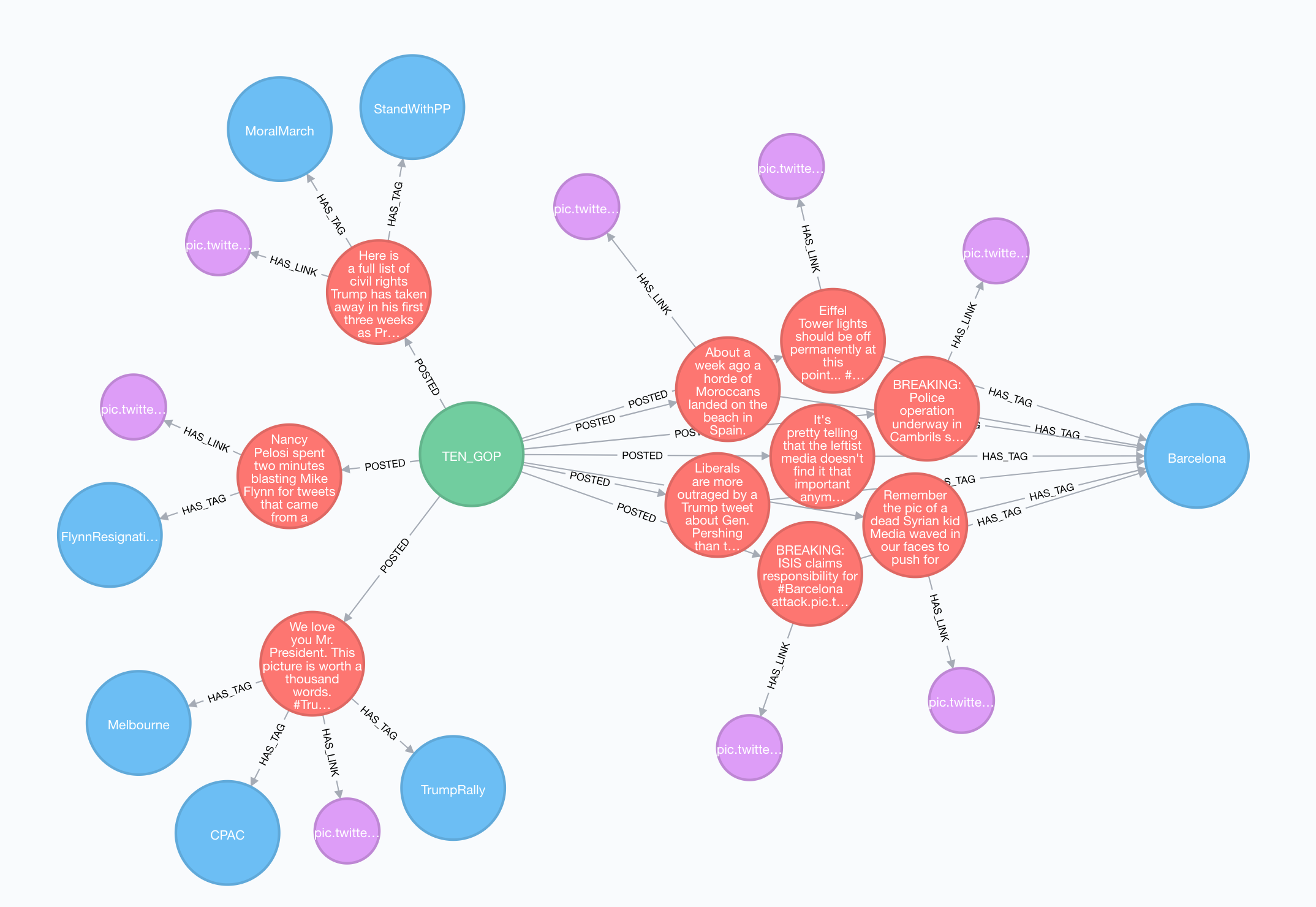
// Tweets for @TEN_GOP
MATCH (u:User)-[:POSTED]->(t:Tweet)-[:HAS_TAG]->(h:Hashtag)
WHERE u.screen_name = "TEN_GOP"
OPTIONAL MATCH (t)-[:HAS_LINK]->(l:Link)
RETURN *
// What are the most common hashtags
MATCH (u:User)-[:POSTED]->(t:Tweet)-[:HAS_TAG]->(ht:Hashtag)
RETURN ht.tag AS hashtag, COUNT(*) AS num
ORDER BY num DESC LIMIT 10
╒══════════════════════╤═══════════╕
│"hashtag" │"num"│
╞══════════════════════╪═══════════╡
│"JugendmitMerkel" │90 │
├──────────────────────┼───────────┤
│"TagderJugend" │89 │
├──────────────────────┼───────────┤
│"politics" │61 │
├──────────────────────┼───────────┤
│"news" │30 │
├──────────────────────┼───────────┤
│"sports" │28 │
├──────────────────────┼───────────┤
│"Merkel" │26 │
├──────────────────────┼───────────┤
│"ColumbianChemicals" │25 │
├──────────────────────┼───────────┤
│"WorldElephantDay" │22 │
├──────────────────────┼───────────┤
│"crime" │21 │
├──────────────────────┼───────────┤
│"UnitedStatesIn3Words"│21 │
└──────────────────────┴───────────┘
// What hashtags are used together most frequently
MATCH (h1:Hashtag)<-[:HAS_TAG]-(t:Tweet)-[:HAS_TAG]->(h2:Hashtag)
WHERE id(h1) < id(h2)
RETURN h1.tag, h2.tag, COUNT(*) AS num ORDER BY num DESC LIMIT 15
╒═════════════════╤══════════════════╤═════╕
│"h1.tag" │"h2.tag" │"num"│
╞═════════════════╪══════════════════╪═════╡
│"JugendmitMerkel"│"TagderJugend" │89 │
├─────────────────┼──────────────────┼─────┤
│"TagderJugend" │"WorldElephantDay"│22 │
├─────────────────┼──────────────────┼─────┤
│"JugendmitMerkel"│"WorldElephantDay"│22 │
├─────────────────┼──────────────────┼─────┤
│"JugendmitMerkel"│"Dschungelkönig" │21 │
├─────────────────┼──────────────────┼─────┤
│"TagderJugend" │"Dschungelkönig" │21 │
├─────────────────┼──────────────────┼─────┤
│"Merkel" │"JugendmitMerkel" │17 │
├─────────────────┼──────────────────┼─────┤
│"Merkel" │"TagderJugend" │17 │
├─────────────────┼──────────────────┼─────┤
│"CDU" │"JugendmitMerkel" │12 │
├─────────────────┼──────────────────┼─────┤
│"CDU" │"TagderJugend" │12 │
├─────────────────┼──────────────────┼─────┤
│"TagderJugend" │"Thailand" │11 │
└─────────────────┴──────────────────┴─────┘
// Most common domains shared in tweets
MATCH (t:Tweet)-[:HAS_LINK]->(u:Link)
WITH t, replace(replace(u.url, "http://", '' ), "https://", '') AS url
RETURN COUNT(t) AS num, head(split(url, "/")) ORDER BY num DESC LIMIT 10
╒═════╤═════════════════════════╕
│"num"│"head(split(url, \"/\"))"│
╞═════╪═════════════════════════╡
│835 │"pic.twitter.com" │
├─────┼─────────────────────────┤
│120 │"bit.ly" │
├─────┼─────────────────────────┤
│105 │"\n\n" │
├─────┼─────────────────────────┤
│100 │"pbs.twimg.com" │
├─────┼─────────────────────────┤
│32 │"vk.com" │
├─────┼─────────────────────────┤
│21 │"riafan.ru" │
├─────┼─────────────────────────┤
│21 │"inforeactor.ru" │
├─────┼─────────────────────────┤
│20 │"nevnov.ru" │
├─────┼─────────────────────────┤
│17 │"goodspb.livejournal.com"│
├─────┼─────────────────────────┤
│15 │"www.fox5atlanta.com" │
└─────┴─────────────────────────┘
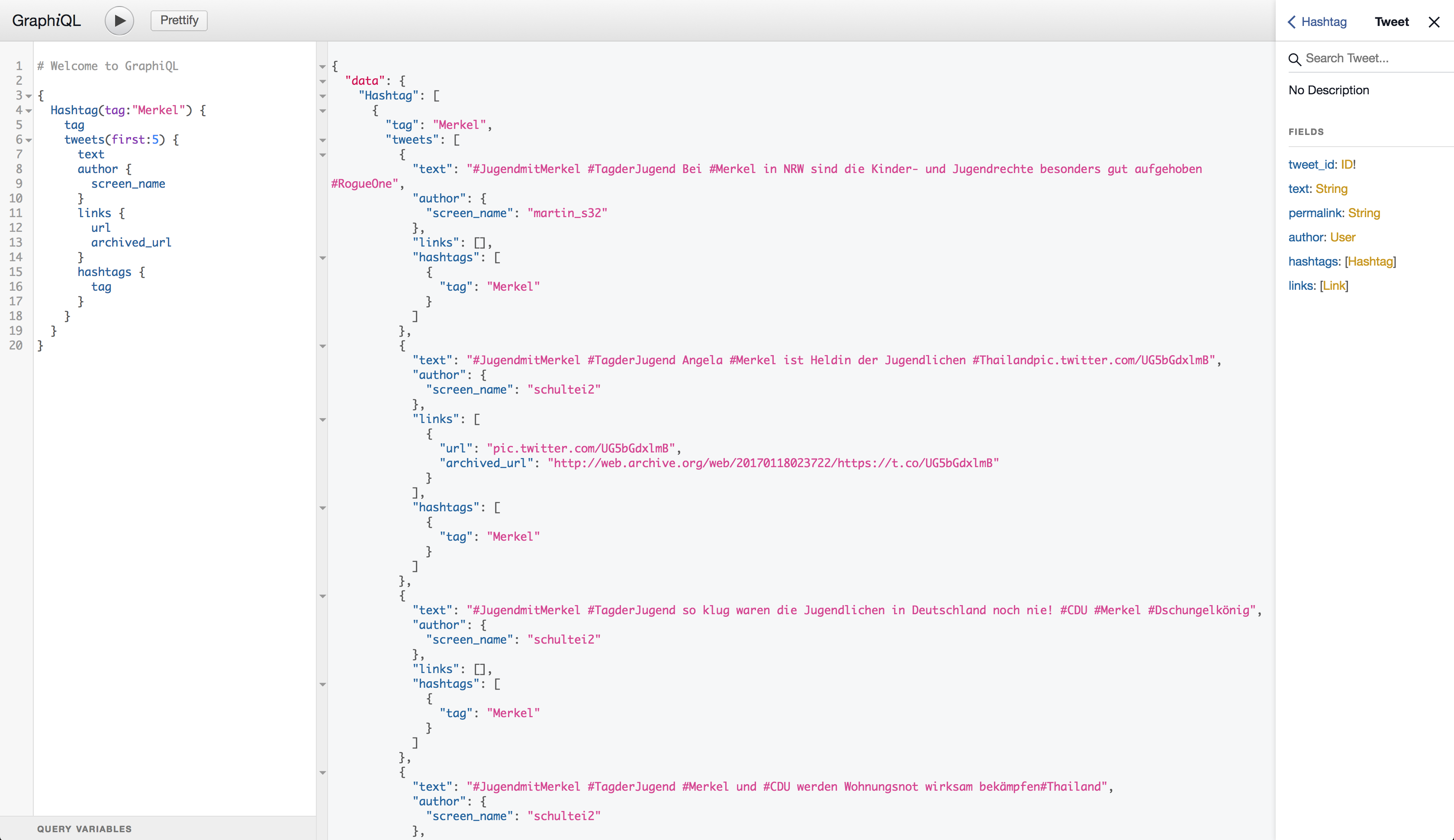
GraphQL API
In addition to querying Neo4j using Cypher directly, we can also take advantage of the neo4j-graphql integrations to easily build a GraphQL API for our tweets.
First, we define a GraphQL schema
type Tweet {
tweet_id: ID!
text: String
permalink: String
author: User @relation(name: "POSTED", direction: "IN")
hashtags: [Hashtag] @relation(name: "HAS_TAG", direction: "OUT")
links: [Link] @relation(name: "HAS_LINK", direction: "OUT")
}
type User {
user_id: ID!
screen_name: String
tweets: [Tweet] @relation(name: "POSTED", direction: "OUT")
}
type Hashtag {
tag: ID!
archived_url: String
tweets(first: Int): [Tweet] @relation(name: "HAS_TAG", direction: "IN")
}
type Link {
url: ID!
archived_url: String
}
type Query {
Hashtag(tag: ID, first: Int, offset: Int): [Hashtag]
}
Our GraphQL schema defines the types and fields available in the data, as well as the entry points for our GraphQL service. In this case we have a single entry point Hashtag, allowing us to search for tweets by hashtag.
With the neo4j-graphql-js integration, the GraphQL schema maps to the graph database model and translates any arbitrary GraphQL query to Cypher, allowing anyone to query the data through the GraphQL API without writing Cypher.
Implementing the GraphQL server is simply a matter of passing the GraphQL query to the integration function in the resolver:
import {neo4jgraphql} from 'neo4j-graphql-js';
const resolvers = {
// root entry point to GraphQL service
Query: {
// fetch movies by title substring
Hashtag(object, params, ctx, resolveInfo) {
// neo4jgraphql inspects the GraphQL query and schema to generate a single Cypher query
// to resolve the GraphQL query. Assuming a Neo4j driver instance exists in the context
// the query is executed against Neo4j
return neo4jgraphql(object, params, ctx, resolveInfo);
}
}
};
React App
One of the advantages of having a GraphQL API is that makes it very easy to build web and mobile applications that consume the GraphQL service. To make the data easily searchable we've make a simple React web app that allows for searching tweets in Neo4j by hashtag.
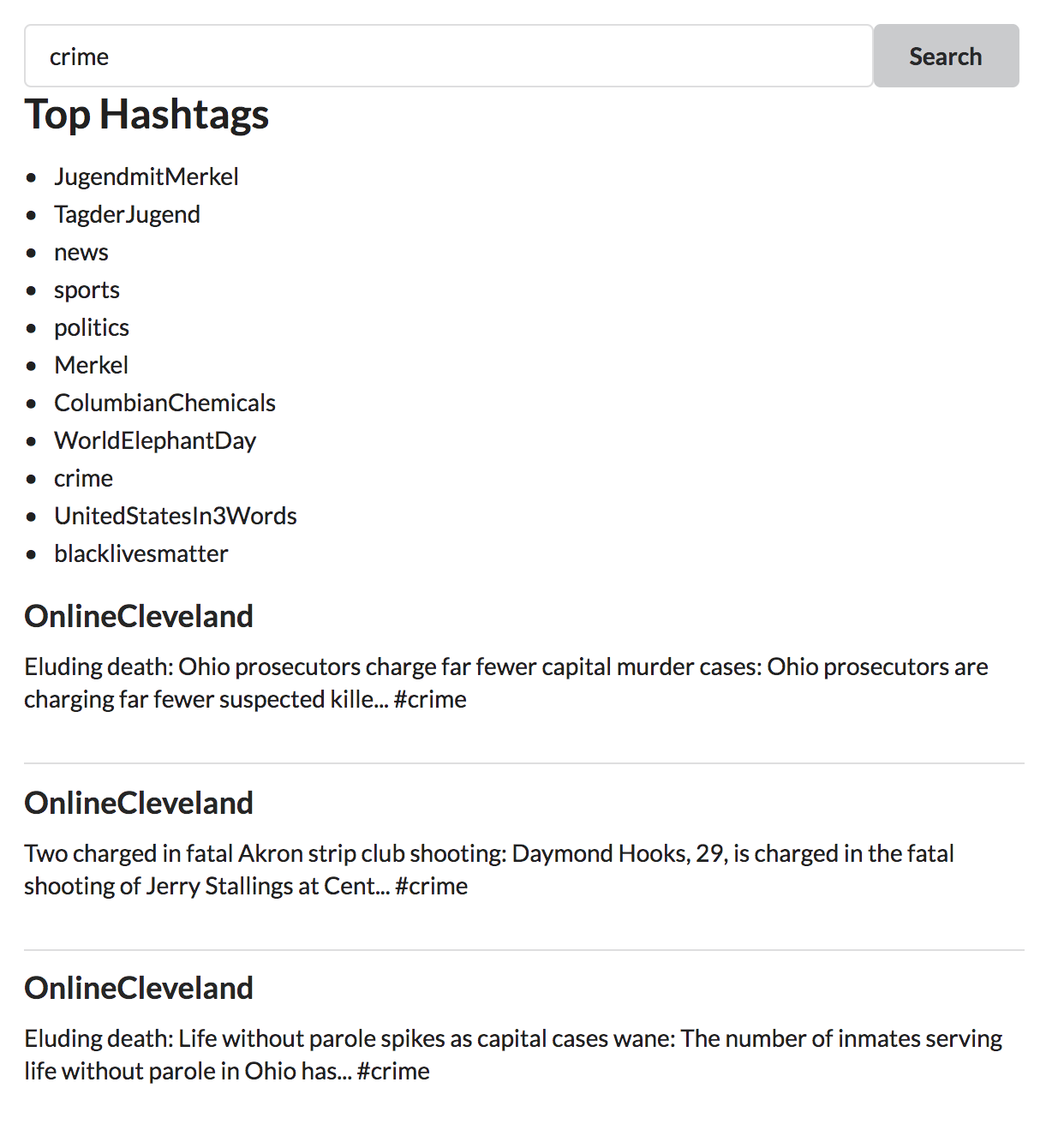
Here we're searching for tweets that contain the hashtag #crime. We can see that a Russia Troll account @OnlineCleveland is tweeting fake news about crimes in Ohio, making it seem that more crime is occurring in Cleveland. Why would a Russia Troll account be tweeting about crime in Cleveland leading up to the election? Typically when voters want a "tough on crime" politician elected they vote Republican...
In this post we've scraped tweet data from Internet Archive, imported in Neo4j for analysis, built a GraphQL API for exposing the data, and a simple GRANDstack app for allowing anyone to easily search the tweets by hashtag.
While we were only able to find a small fraction of the tweets posted by the Russian Twitter Troll accounts, we will continue to explore options for finding more of the data ;-)
All code is available on Github at https://github.com/johnymontana/russian-twitter-trolls.
Stay Updated
Get notified about new posts and videos